My BAIN Blog
Willkommen zu meinem Lerntagebuch
Ich freue mich, dass Du da bist. Ich schreibe hier über meine Erfahrungen im Kurs Bibliotheks- und Archivinformatik.
Posts
-
Abschlussartikel
Tschüss und bis ein anderes Mal!
Pfiuuu! Was für ein Semester! (Und was überhaupt für einen Jahr!) So erleichtert wie jetzt bin ich noch nie gewesen, dass der Semester ein Ende nimmt.
-
10 Linked Data
Aktuelle Datenmodelle für Metadaten
-
9 Suchmaschinen und Discovery-Systeme 2/2
Nachtrag LIDO
Die Dozenten machten als Erstes ein kleines Nachtrag zu LIDO, da anscheineind ein Angstgefühl in der letzen Lektion verbreitet wurde. Einiges habe ich schon in meinem Blog über LIDO geschrieben gehabt. Deswegen werde ich hier nicht vertieft darauf eingehen, sondern nur Ergänzungen zu den Punkten, die ich eventuell nicht beschrieben hatte, geben. LIDO ist leztendlich einfach ein XML-Format, mit welchem man mit den gleichen Tools und Methoden wie bei anderen Formate verwenden kann. Das Format ist nicht unbedingt komplizierter, sondern ist einfach anders als andere Formate aufgebaut. Hingegen ist CIDO CRM wirklich kompliziert. Im blog erwähnte ich den Vorteil von Linked Data-Strutkuren, hinzu kommen noch die Verwendung von kontrollierten Ontologien/Vokabularen und die Wiederverwendung von Entitäten wie Ereignissen.
-
8 Suchmaschinen und Discovery-Systeme Teil 1
Nachtrag zu Metadaten modellieren und Schnittstellen nutzen
-
Anreicherung mit GND-Einträge
Aufgabe Anreicherung mit lobid-gnd
Man öffnet OpenRefine und somit auch das bis jetzt bearbeiteten Projekt in OpenRefine. Anhand der allgemeine Anleitung im Blog von lobid-gnd wurden die Autoren Namen mit der GND abgestummen (reconcialiate). Dies mit folgende Schritte:
- Spalte Autoren auswählen
- Dann auf “Reconcialiate” und > “Start Reconciliation”
- Man muss den Service hinzufügen, dafür klickt man auf “Add Standard Service…”
- und gibt https://lobid.org/hnd/reconcile als URL ein.
-
7 Metadaten modellieren und Schnittstellen nutzen 2/2
Zwischenstand – neues Schaubild
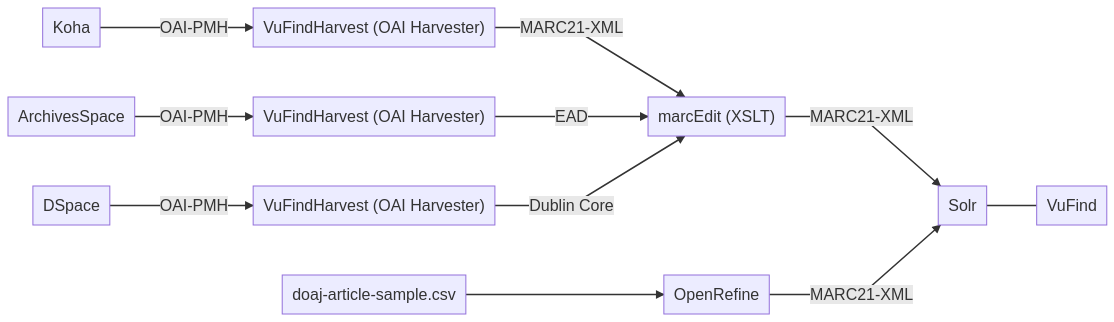
-
6 Tag Metadaten modellieren und Schnittstellen nutzen 1/2
Schaubild
Den Schaubild vom Tag 1 wurde überarbeitet. Damals wurde geplant mit dem OAI Harverster metha zu arbeiten, aber da funktionniert das «Ernten» nicht ganz einwandfrei und deswegen wurde von den Dozenten stattdessen VuFindHarvest ausgewählt. Letzeres ist Teil von VuFind, kann aber eigenständig verwendet werden. Bis jetzt haben wird die drei Systeme aus diesem Schaubild kennengelernt: Koha, ArchivesSpace und DSpace und gelernt, dass alle Systeme eine OAI-PHM Schnittstelle haben. Mit diesen haben wir in dieser Lektion Dateien in drei verschiedene Formate (MARCXML, EAD und Dublin Core) heruntergeladen. Mit MarcEdit werden wir über einen Crosswalk die Dateien in MARC21-XML umwandeln. Solr ist Teil der VuFind Software und ist eine Volltextsuchmaschine, welche von vielen Webanwendungen benutzt wird. Solr ist keine Archiv- oder Bibliotheksspezifische Software. Sie wird in sehr vielen Websiten benutzt – z.B. von Netflix und Amazon – und ist eine der bekannteste Suchmaschine neben Elasticsearch. Ich bin gespannt über diese mehr kennenzulernen, da wir bis jetzt vor allem spezifische Anwendungen benutzt haben.
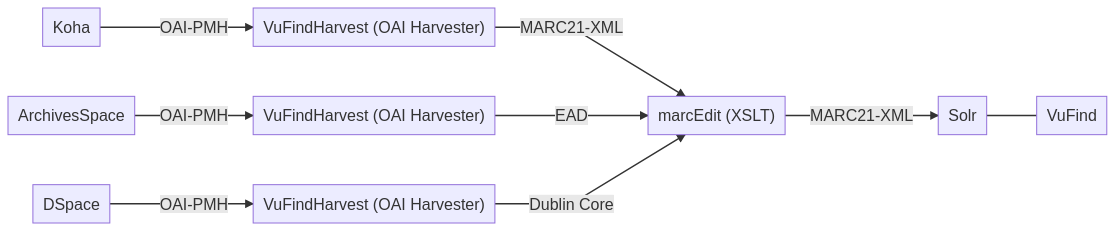
-
5 Funktion und Aufbau von Archivsystemen (2/2) / Repository-Software für Publikationen und Forschungsdaten
Begrifflichkeiten für Übung Bedienung
Accession, Resource und Archival Objekt sind zentrale Begriffe für die archivirische Tätigkeit, besonders hier für ArchivesSpace von Bedeutung. Mit diesen hatte ich selber bei dem letzten Mal Mühe. Dank diesen Erklärungen ist es mir ein bisschen klarer geworden.
-
4 Funktion und Aufbau von Archivsystemen 1/2
Wir besprachen die Funktionen sowie den Aufbau von Archivsystemen und lernten zusammen durch Übungen ArchivsSpace kennen.
-
3 Funktion und Aufbau von Bibliothekssystemen 2/2
Weiteres Kennenlernen von Koha
Mit den folgenden Übungen konnten mit Koha und seine Funktionalitäten experimentieren.
-
2 Funktion und Aufbau von Bibliothekssystemen 1/2
Versionskontrolle mit Git & Funktion und Aufbau von Bibliothekssystemen 1/2
Heute ging es einerseits um die Kommentare zu den Lerntagebücher, Fragen um dem Blog und einer Versionskontrolle mit Git, anderseits gewannen wir einen Einblick in der Funktion und der Aufbau von Bibliothekssystemen mit Metadatenstandards in Bilbiotheken (MARC21) und mit der Installation und Konfiguration von Koha.
-
1 Organisatorisches & Technische Grundlagen
CodiMD und Markdown
Neben (und eigentlich auch während) der Vorlesungen wird CodiMD für ein gemeinsames Dokument benutzt, einerseits als Grundgerüst für die Plräsentation der Dozenten, anderseits für Notizen und Austauschmöglickeit. Alle dürfen den Dokument benutzten und dies mit der Markdown Formatierung. Von den Dozenten wird dazu einen Skript als Blog geführt, welcher jetzt die Inhalte aus dem letzen Semester beinhaltet. Da werden im Verlauf des Semesters die Inhalte aus dem gemeinsamen Dokument nach und nach zusammengeführt. Der Grund dafür ist, dass CodiMD nicht für die dauerhafte Benutztung gemacht ist. Auch ermöglicht es uns einfacher durch die Inhalte zu suchen und diese in unserem eigenen Blog zu referenzieren.
-
Einführungsartikel
Et c'est parti!
Wie der Heading es schon sagt, es geht mit einem neuen Semester wieder los. Und hier genauer um das Modul Bibliotheks- und Archivinformatik (BAIN).
Une petite introduction
Eigentlich habe ich schon studiert, in diesem Bachelor kamm ich 2017 mit schon einem Master in Fine Arts in der Tasche. Nach dem Gymnasium und dem Bachlor- und dem Masterstudium hatte ich allerdings genug von Nebenjobs, welche mich intelektuell nicht beanspruchten. Nach 10 Jahren im Detailhandel hatte ich genug und wollte was machen, wo ich immer wieder neues lernen kann und wo (hoffentlich) ich mit meiner Meinung zu was grösseren beitragen kann. Nach einer Stunde mit einer Berufberaterin war fast schon entschieden: «Ich werde Information Science studieren». Für mich klang das Studium super, vor allem aus praktischen Gründen. Einen Diplom mit viele Möglichkeiten in der Arbeitswelt, ein vermutlich anständiges Lohn und die Möglichkeit Teilzeit zu arbeiten. Ja, Teilzeit, weil für mich kam nicht in Frage, komplett mit Kunst aufzuhören. Sondern mein Ziel war nämlich Kunst machen zu können, ohne Existenzängste leben zu müssen und ohne das Gefühl zu haben, dass ich meine Zeit anderswo besser investieren konnte. Was aber das Studium besonders interessant für mich machte, waren die technische Aspekte mit Informatik und ein bisschen Programmieren – das hat mich immer interessiert – in Kombination mit einem kulturelles Berufsfeld. Ich sah die Möglichkeit, ohne Lehren oder Kuratieren, mit Kulturgüter zu arbeiten. Das motivierte mich.
subscribe via RSS