4 Funktion und Aufbau von Archivsystemen 1/2
Wir besprachen die Funktionen sowie den Aufbau von Archivsystemen und lernten zusammen durch Übungen ArchivsSpace kennen.
Metadatenstandards in Archiven (ISAD(G) und EAD)
ISAD(G)
ISAD(G) ist eine wichtige Basis für die Bedienung von Archivsysteme, da dieser Standard und somit auch Archivsysteme anders als Bibliotheksysteme und ihre Standards funktionnieren. Als Archivsysteme entwickelt worden sind, orientierte sich dabei die Datenstruktur an analogen Findmitteln (zum Beispiel Findbücher und Zettelkästen). Es wurde damit versucht die analoge Arbeitsweise abzubilden. In 1994 wurde der Verzeichnungsstandard ISAD(G), welcher für “International Standard Archival Description (General)” steht, eingeführt und in 2000 überarbeitet. Hier gilt eine mehrstufige Verzwichnung im Provinienzprinzip, mit welchem den Entstehungzusammenhang abgebildet werden soll. So wird nicht als erstes das Medium beschrieben, sonder wie dieses zum Archiv kamm. Am Beispiel des Deutschen Literaturarchiv Marbach, wenn ein Nachlass oder ein Vorlass im Archiv kommt, wird unter anderem versucht herauszufinden, wie die Schriften aufgebaut worden sind, wie den Erkenntnissprozess war und was als Inspirationsquelle galt. Damit werden die Medien sortiert und an den Bestandsbildern «angehängt». Im Grunde genommen, wird den Kontext der Übergabe beschrieben. Dies ist für Bibliotheken nicht interessant, sondern nur das Medium. Dieser Unterschied hat vermutlich damit was zu tun, dass Archive meist mit Unikate zu tun haben und dadurch wird mehr Zeit für eine Erschliessung investiert.
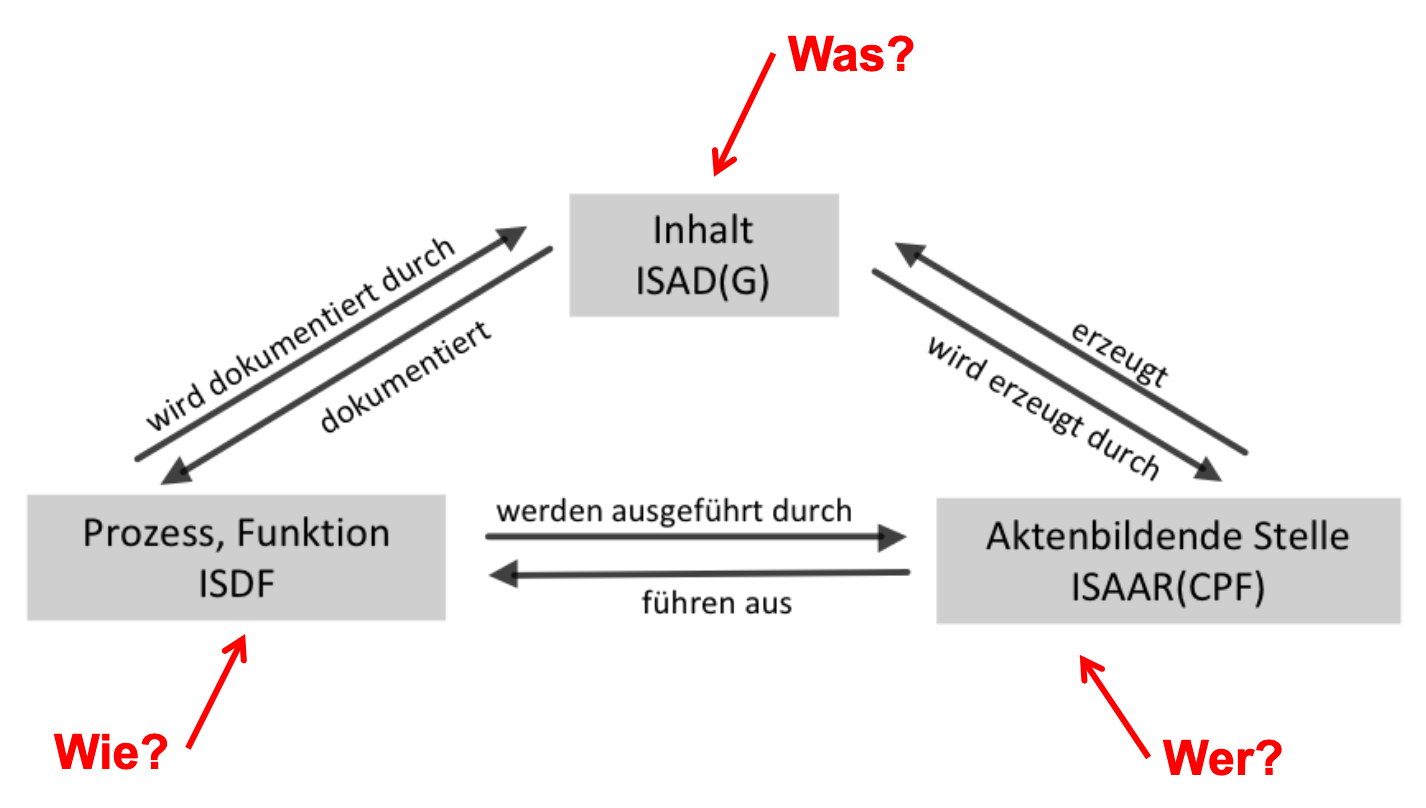
Dieser Datenmodell zeigt die Beziehung zwischen archivirische Standards, welche die Frage nach dem «Was?», «Wie?» und «Wer?» beantworten. Da steht ISAD(G) für das «Was» und somit «Was wird im Entscheidungsprozess an Unterlagen produziert? Dossier, das sämtliche Records zu diesem Antrag vereint» (Tobias Wildi, 2015).
Quelle des Bildes: Docuteam (Tobias Wildi) / Records im Kontext, Kontextualisierung 2.0 mit Matterhorn METS / 9. AUdS-Tagung Wien 2015
Für die Beschreibung besitz der Standard 26 Verzeichnungselemente, welche in 7 Informationsbereiche unterteilt werden:
- Identifikation
- Kontext
- Inhalt und innere Ordnung
- Zugangs- und Benutzungsbedingungen: diese spielen im Bereich von Archive eine besondere Rolle, da sie dienen dem Schutz des Objektes und/oder von Personen.
- Sachverwandte Unterlagen
- Anmerkungen
- Kontrolle
Von besonderer Bedeutung sind vor allem diese 6 Pflichtfelder:
- Signatur
- Titel
- Provenienz
- Entstehungszeitraum
- Umfang
- Verzeichnungsstufe: im Standard gibt es mehere Stufen/Ebenen, aus welchen sich eine Baumstrutkur – aus Bestand > Serie > Dossier > Dokument – ergibt und welche die Zusammenhänge definieren. In der nächste Übung «Archivkataloge» werden nach dem Dozent die Verzeichnungsstufen und ihre Funktionen klarer.
Die Grenzen von ISAD(G): Aufgrund folgende Grenzen von ISAD(G) wird ein neues Standard namens «Records in Context» (RiC) entwickelt, welches an Linked Data orientiert ist.
- Einzelne Datensätze sind zum Teil nur im Kontext verständlich. Das heisst ohne den beschrieben Kontext eines Dokument, kann man mit dieser nicht viel anfangen, wie mit einem Protokoll der nur als «Protokoll» betitelt ist und alle Informationen über die entsprenchende Generalversammlung nicht zu verfügung stehen, da diese auf eine höhrere Ebene beschrieben wird. Dies kann dann für den Ausstausch von Daten schwierig, weil sie immer umgebaut werden müssen.
- Die Tektonik ist eindimensional und somit die Mehrfachzuordnung nicht möglich. Man muss sehr gut nachvollziehen, wie einen Archivar gearbeitet hat, um zu wissen wie neue Unterlagen eingebunden werden sollen.
- Ein Problem, welches vor allem mit dem Entstehungszeitraum des Standards zu tun hat, ist, ISAD(G) dieser keine Vorgaben für die digitale Langzeitarchivierung anbietet.
Normdaten mit ISAD(G)
- Das ergänzende Standard «International Standard Archival Authority Record for Corporate Bodies, Persons, and Families” - kurz ISAAR(CPF) – für Normdateien im Archivbereich verabschiedet und ermöglicht die Beschreibung von Aktenbildner. Allerdings wird dieser sehr selten in Archive benutzt, dies aufgrund den zusätzlichen Aufwand, dass es bedeuten würde. Der Standard wurde zwischen 1993-1995 entwickel und dann in 2004 für die aktuelle Version überarbeitet. Es gibt einen Trend, in welchem Archive mit Bibliotheken versuchen, gemeinsame Standards zu verwenden. Nach Herr Meyer hat diese glückliche Entwicklung viel mit der Digitalisierung zu tun, da Archive sich da immer mehr an Bibliotheke orientieren, welche in diesem Bereich einen Vorsprung haben. Herr Lohmeier erwähnte als Beispiel auch die ETH-Bibliothek, die natürlich eine Bibliothek ist, aber zugleich auch ein Archiv. Auch in seinem Hochschularchiv verwendet die ETH-Bibliothek die GND für Normdaten.
- Der oben erwähnten Standard RiC, welcher sich in Entwicklung befindet, soll neue und mehrfache Beziehungen zwischen Entitäten ermöglichen.
Fun Fact: Unter dem Namen Ensemen wurde eine Projektgruppe innerhalb des VSA gegründet, welche die neuen Grundlagen im Bereich Metadaten- und Datenverwaltung zu erarbeitet und eine schweizerische Umsetzung von RiC entwickelt. Dies aufgrund des technischen Fortschritt und den wachsende Menge an digitale Daten, bei welchen die aktuellen Anforderungen nicht mehr für ein modernes Archiv ausreichen.
Übung Archivkataloge
In Teilgruppensitzungen suchten wir nach:
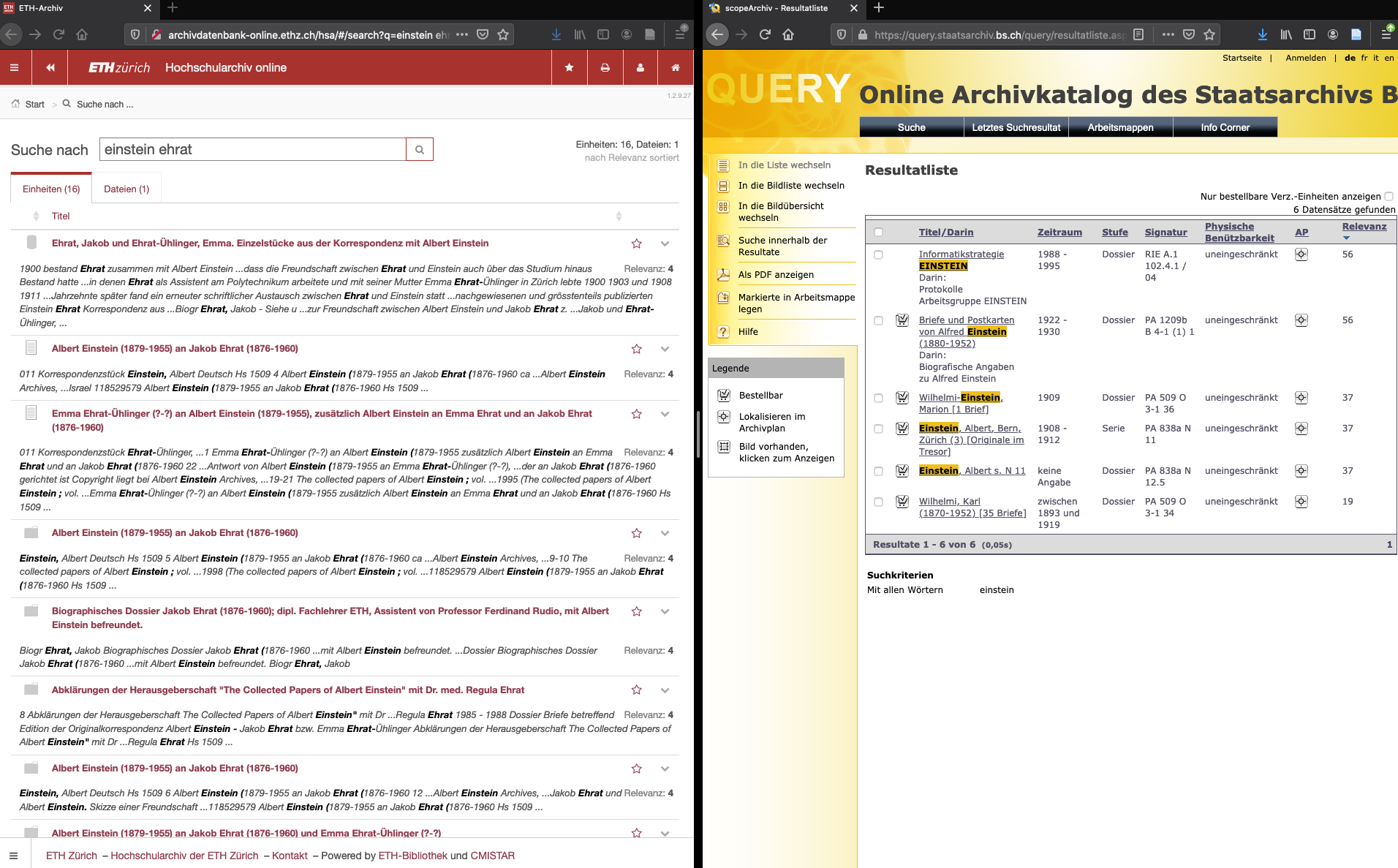
Einsteinim Online Archivkatalog des Staatsarchivs BSEinstein Ehratim Hochschularchiv ETH Zürich
und versuchten diese Fragen zu beantworten:
- Welche Informationen enthält die Trefferliste? ETH: Signatur, Entstehungszeitraum, Verzeichnisstufe, Relevanz, physische Benutzbarkeit
- Welche Verzeichnungsstufen sind vertreten? v.a. Dossier und Dokument, aber auch Fonds und Bestand
- Sind die ISAD(G)-Informationsbereiche erkennbar? -
- Decken sich die grundlegenden Informationen oder gibt es bemerkenswerte Unterschiede? Infos scheinen sehr ähnlich, Darstellung bei Basel aber meiner Meinung nach übersichtlicher
- Worin liegen die zentralen Unterschiede zu einem Bibliothekskatalog?
Die Antworten unsere Gruppe habe ich unter den Fragen eingefügt. Leider war für uns die Zeit zur knapp und konnte somit nicht alle Fragen beantworten. Generell ist der Klasse der Meinung, dass der Katalog von Basel übersichtlicher ist, auch wenn dieser der ETH moderner wirkt. Als Bemerkung von Herr Meyer, lernen wir, dass die alle Felder in ISAD(G) pflicht sind und werden deswegen nicht immer befüllt. Somit sind nicht für jedes Dokument alle Informationen verfügbar und man muss zum Teil die Verzeichnisstufe wechseln, die Information zu erhalten.
EAD
Encoded Archival Description (EAD) ist ein XML-Standard und Ausstauschformat. Es gibt davon veschiedene Versionen. EAD wird verwendet, um Datensätze aus Archive zu holen oder Daten auszutauschen. Das Format ist relativ offen und lässt viele Wahlmöglichkeiten zu. Aus diesem Grundgibt es oft Anwendungsprofile, um zu definieren, welche Werte in einer Zusammenführung zugelassen werden.
Herr Lohmeier verweist bei Interesse auf eine Einführung zu EAD: Nicolas Moretto (2014): EAD und digitalisiertes Archivgut
Aktuelle Entwicklungen
- Umstieg von ISAD(G) auf RiC wird vermutlich kommen. Dies aber wird mit viel Aufwand und einen Systemwechsel verbunden sein. Man rechnet somit mit grossen Migrationsprojekten.
- Volltexte werden immer mehr generiert, weil die Optical Character Recognition (OCR) immer besser wird. Auch die automatisierte Anreicherung von Volltexten durch Named Entity Recognition wird zunehmend in Archive eingesetzt.
- In Wikidata werden Online-Findmittel über Property Archives at verzeichnet. Beispiel Albert Einstein in Wikidata. Wikidata aus archivierische Sicht wichtig. Unter «Archives at» können Archive sich verzeichnen und ihre Sammlung als Eintrag einfügen.
- In der Schweiz gibt es auch die Vernetzungsinitiative Metagrid und weitere Dienste von histHub, einer Forschungsplattform für die Historischen Wissenschaften.
- Auch interessant als Literaturempfehlung für eine Diskussion: Umfrage “Was sich Historiker*innen von Archiven wünschen”. Danke dafür! Diese Empfehlung würde ich gerne folgen, allerdings vermutlich eher während der Semesterpause, da dieser Blogeintrag sich interessanten Details in der Länge zieht.
Installation und Konfiguration von ArchivesSpace
Einführung in ArchivesSpace
ArchivesSpace ist eine Open-Source-Software für Archivinformationssysteme. Dessen code findet man bei GitHub. Es ist eine wichtige Instanz, was sich durch seine Anzahl an Mitglieder ausfzeigt: 400 Mitglieder, wodruch knapp 5 Vollzeitstellen finanziert werden können. ArchivesSpace ist institutionell bei Lyrasis verankert, ein internationalen Bibliotheksnetzwerk, welcher allerdings vorwiegend in den USA aktiv ist. Zwei weitere Unternhemen bieten einem professionellen Support für ArchivesSpace. Da die Software nicht nur von einer Institution abhängig ist, ist ein Zeichen für ihre Nachhaltigkeit.
Metadaten in ArchivesSpace:
ArchivesSpace basiert auf den Standards DACS, ISAD(G) und ISAAR(CPF) und unterstüzt den Import/Export in EAD, MARCXML und METS. DACS ist ein Standard aus der USA, worauf ISAD(G) und ISAAR(CPF) basieren. Es Aufgrund dieser Amerikanisierung können wir auf gewisse Herausforderungen mit ISAD(G) kommen, da gewisse Anforderungen nicht immer passend sind.
Exkurs zur Systemadministration
Wir haben auf unsere Server bereits Koha installiert. Gibt es Probleme, wenn wir ArchivesSpace zusätzlich installieren? Es können Konflikte im Bereich der Versionen oder Ressourcen bei der Nutzung von mehere Systeme vorkommen. Dies vor allem, wenn gleiche Ports und viel Leistung von einem System benutzt wird. Es empfiehlt sich somit jedes System in einer eigenen Umgebung zu installieren. In unserem Fall vetragen sich Koha und ArchivesSpace gut, da sie nicht den gleichen Ports benutzten, und somit wird ASpace einfach zusätzulich installiert. Wenn man aber in der Realität mit beide Systeme arbeiten möchte, dann werden Sie separat installiert.
Note aus dem Skript: Es könnte Konflikte geben, wenn die Systeme unterschiedliche Versionen der gleichen Programmiersprache (z.B. Java, PHP) oder der Datenbank (z.B. MySQL, PostgreSQL) benötigen. Es könnten auch die Ressourcen (insbesondere Arbeitsspeicher) knapp werden. Um den Wartungsaufwand zu reduzieren und Ressourcen zu sparen, werden üblicherwese virtuelle Maschinen oder Container eingesetzt.
Grundkonfiguration ArchivesSpace
im Terminal starten
Wichtig zu wissen ist, dass ArchivesSpace immer neu gestartet werden muss, wenn wir den System neu starten, und nur funktionniert wenn dieser Prozess im offener Terminal läuft. Hier der Befehl dafür, wo im Ordner ArchivesSpace die Shell Datei aufgerufen wird:
archivesspace/archivesspace.sh
Nachtrag: dies können wir umgehen, indem ein & am Ende des Aufrufsbefehl eingefüht wird.
Grundkonfiguration
Nach dem ersten Login erscheint die Meldung:
To create your first Repository, click the System menu above and then Manage Repositories.
Hier müussen wir den Button Create Repository betätigen, um ein Repository zu erstellen. Pflichtfelder dafür sind nur Repository Short Name und Repository Name. Für uns ist zusätzlich Checkbox Publish? anzwählen, damit die Daten sozusagen öffentlich (im «public interface») unter http://localhost:8081 erreichbar sind.
Übung: Datensätze erstellen
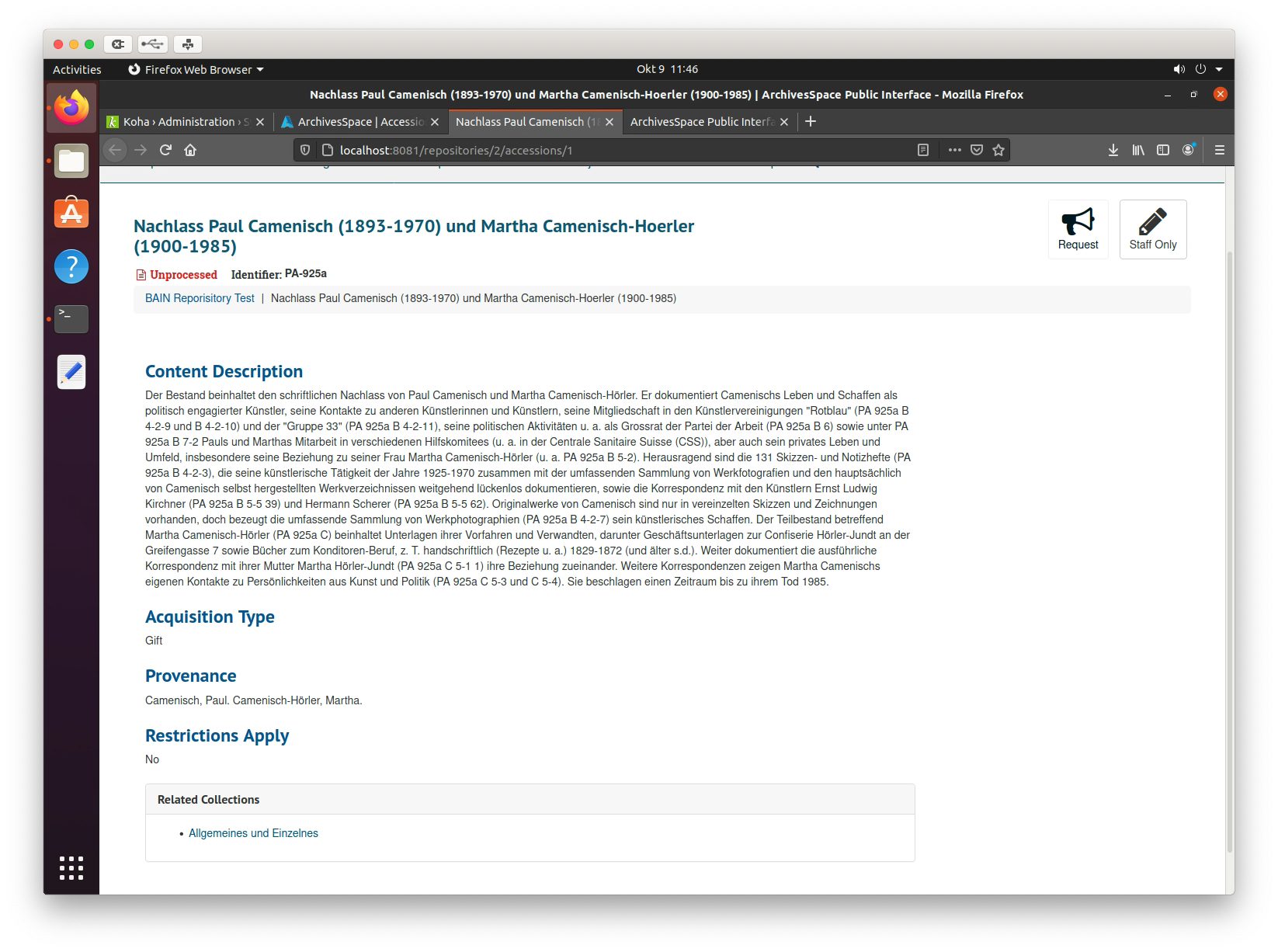
- Aufgabe: Wir mussten in Gruppen einen eigenen Datensatz in ArchivesSpace erstellen. Dafür durfte man Archivdaten von Institutionen übernehmen, oder mindestens es zu versuchen. In der Gruppe haben wir einen Bestand aus dem Staatsarchiv Basel-Stadt dafür ausgewählt: den Nachlass Paul Camenisch und Martha Camenisch Hoeler. Ziel war, dass die Datensätze in der öffentliche Ansicht erscheinen (unter http://localhost:8081). Die Screenshots dazu finden Sie weiter unten.
- Erkenntnisse: Es war nicht sehr einfach zu verstehen, welches Teil vom Staatsarchiv zu welchem Abschnitt in ASpace gehört. Ob wir richtig übernommen haben, wissen wir nicht. Oder zumindenst ich leider nicht. Die Sprache war da ein grosses Problem. Wir haben alle Informationen aus dem Staatsarchiv versucht zu übernehmen, indem wir die Felder in ArchivesSpace Punkt für Punkt übersetzten und diese mit den entsprechende Informationen zum Nachlass aussuchten. In Diskussion mit der Gruppe platzierten wir gewissen Felder in ArchivesSpace um, wenn wir doch dachten, dass es nicht am richtigen Ort war. Grundsätzlich hat es geklappt und was wir erschlossen haben, war auch einsehbar. Ich glaube allerdings, dass es nicht möglich fehlerfrei mit dem System intuitiv zu arbeiten, wenn man nicht genau die Bedeutung der Felder in ASpaces kennt und dazu auch keine tatsächliche Praxiserfahrung mit der Erschliessung in Archiven hat.

Quellen: Docuteam: Records im Kontext, Kontextualisierung 2.0 mit Matterhorn METS, ISAAR(CPF), Ensemen, Skript