9 Suchmaschinen und Discovery-Systeme 2/2
Nachtrag LIDO
Die Dozenten machten als Erstes ein kleines Nachtrag zu LIDO, da anscheineind ein Angstgefühl in der letzen Lektion verbreitet wurde. Einiges habe ich schon in meinem Blog über LIDO geschrieben gehabt. Deswegen werde ich hier nicht vertieft darauf eingehen, sondern nur Ergänzungen zu den Punkten, die ich eventuell nicht beschrieben hatte, geben. LIDO ist leztendlich einfach ein XML-Format, mit welchem man mit den gleichen Tools und Methoden wie bei anderen Formate verwenden kann. Das Format ist nicht unbedingt komplizierter, sondern ist einfach anders als andere Formate aufgebaut. Hingegen ist CIDO CRM wirklich kompliziert. Im blog erwähnte ich den Vorteil von Linked Data-Strutkuren, hinzu kommen noch die Verwendung von kontrollierten Ontologien/Vokabularen und die Wiederverwendung von Entitäten wie Ereignissen.
Als Antwort einer Anmerkung aus Gaby’s Blogeintrag der letzten Sitzung gehen die Dozente noch auf einer Recherche zur Transformation von LIDO in andere Formate mit Crosswalks ein. Vielleicht ist es mir auch irgendwann hilfreich, also möchte ich hier zu diesen Referenzen verlinken.
Suchmaschinen und Discovery-Systeme 2/2
Solr
Suchmaschine Solr als Basis für das Discoverysystem VuFind ist zusammen mit Elasticsearch den Industriestandard. Die beide Suchmaschine sind eben die am meistbenutzenden Suchmaschine für Webseiten und wo Volltextsuche gebraucht werden. Im Normalfall wird vor einem Import in einem Schema festgelegt, welche Felder es gibt und welchen Datentypen diese beinhalten dürfen. Letzeres ist wichtig, damit Geokoordinaten oder einem Datum durchsuchbar sind. So kann man nach Räume oder Zeiträume suchen und nicht nur nach Textfelder. Allerdings kann man theoretisch auch Daten ohne Schema – als «Schemaless» – in Solr importieren und man hat eine Volltextsuche, aber dies ohne Kontrolle. Solar ist ohne Suchoberfläche per se gegeben: es gibt zwar eine, die intergriert ist, aber nur für Demo-Zwecken gedacht. Also nur zum Testen ob das System funktionniert. Man braucht also eine eigene Webseite und eigene Tools, um Solr für die Nutzung zu integrieren. Dazu basiert das Discoverysystem VuFind auf Solr, sowie auch viele Andere wie z.B. Ex Libris Primo.
Unterschied zwischen Suchindex (Solr) und Datenbank (MySQL)
Die Unterschiede sind doch grösser als man meinen könnte, obwohl in beide Systeme Daten importiert werden und aufgerufen werden.
- Die Datenstrutkur ist ein wesentlichen Unterschied zwischen Suchindex und Datenbank. Bei einem Suchindex handelt es sich um eine flache Dokumentstruktur, das heisst jedes Dokument steht für sich allein ohne Verbindung zu Anderen. Hingegen hat man bei einer Datenbank relationale Datensätze, so können Daten auf einander verweisen.
- Auch gibt es Unterschiede bei der Suchanfrage. Bei einer Datenbank gibt es nur einen reinen Glyphenvergleich, welches mit Operatoren (AND, OR, etc.) unterstützt werden kann, so wird die Angabe zu den Daten 1:1 verglichen und den zutreffenden Ergebnis herausgegeben. Bei einem Suchindex wie Solr wird eine lexikalische Suche durchgeführt, das heisst das eine Angabe wird als Begriff mit einer Grammatik verstanden und so erhält man sinngemässe Treffer (nicht nur 1:1 Resultate).
- Dafür geben Datenbanken den Vorteil, dass Daten nach Ihre Konsistenz überprüft werden. Dies ist nicht der Fall bei einem Suchindex, was bedeutet, dass wenn ein Fehler beim Indexieren aufretten sollte und den Server z.B. abbricht, muss der Suchindex neu aufgebaut werden. Somit ist ein Suchindex eine Art flüchtiger Speicher, wo Daten nicht auf die Dauer wie bei einer Datenbank sicher gespeichert werden können.
- In einem Suchindex sind die Daten statisch und können somit nicht verändert oder aktualisiert werden. Einzig was möglich ist, ist eine Kopie eines Datensatz zu haben, dieser nach Bearbeitung im System zu laden und den «alten» Datensatz als gelöscht zu markieren, damit dieser nicht in Suchergenisse vorkommt. Die Aktualisierzung von Daten ist in Datenbanken möglich und so spart man sich immer Kopien machen zu müssen.
Schlussendlich diese Unterschiede zwischen Suchindex wie Solr und Datenbanken wie MySQl deffinieren auch ganz einfach ihre Einsatzwecke. Wo Ziel eines Suchindexes den Retrieval (bzw. die Suche) ist, ist das Ziel einer Datenbank die Speicherung (Storage). Die Storage-Funktion von Datenbanken wird auch CRUD gennant, was für Create Read Update Delete steht.
Sichtung von Solr in VuFind
Nun schauen wir uns Solr in der Praxis ein, dabei ist zu achten, dass diese Links nur in der virtuellen Maschine funktionnieren. Die Dozenten geben uns ein ersten kleinen Einblick – da wir Gäste haben – auf dem eigene Rechner.
- Administrationsoberfläche: http://localhost:8983
- Bibliografische Daten im Index “biblio”: http://localhost:8983/solr/#/biblio
- Technische Suchoberfläche in Solr für Index “biblio”: http://localhost:8983/solr/#/biblio/query
- Schema des Index “biblio”: http://localhost:8983/solr/#/biblio/schema
- Erläuterung der VuFind-Felder in VuFind Doku: https://vufind.org/wiki/development:architecture:solr_index_schema
In den unteren Bilder ist 1. die Query von Solr und 2. Informationen zum Schema, welche grob zeigen wie die Felder konfiguriert sind, zu sehen.
Hinweis von den Dozenten auf einem guten Tutorial im offiziellen Handbuch von Solr, wenn man mehr über Solr wissen möchte.
Übung: Suche in VuFind vs. Suche in Solr
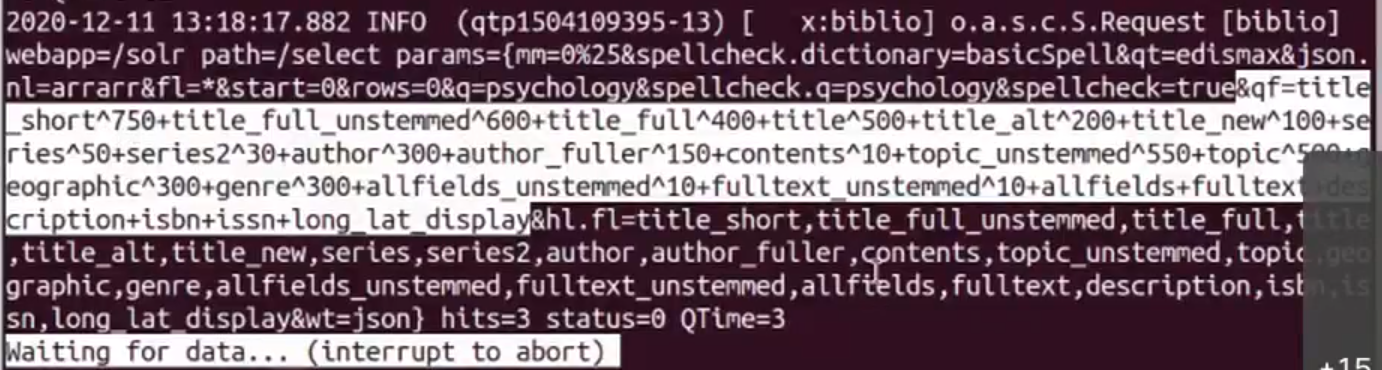
In dieser Übung betrachteten wir die Unterschiede der Suche zwischen VuFind (suche nach psychology) und Solr (Suche im Query nach allfields:psychology) und schauten parellel die Logdatei im Terminal mit less +F /usr/local/vufind/solr/vufind/logs/solr.log.
Himmerhin kammen schon mal die gleichen Resultate in VuFind wie im Solr vor: drei Resultate, wo das Wort im Titel sowie unter «Subject» vorkommt. Wir fanden, dass im Discoverysystem VuFind die Anzeige der Ergebnisse viel übersichtlicher ist, auch wird was zutrifft ge-highlighted. Dies wird in Solr nicht angezeigt, sondern nur die Anzahl an Treffer und alle Felder der gefundenen Dokumenten.
In der Diskussion zeigte uns Herr Lohmeier die Logdatei von Solr im Terminal. Er führte eine Suche in Solr und dann in Vufind. Man konnte zusammen beobachten, wie die Suche durch dem Ranking bewertet wird. Zum Beispiel bei der Suche in VuFind hat «title_short» eine Gewichtung von 750, «title_full» von 400 und der ersten Author eine von 300. Beide Dozente diskutierten über die Schwierigkeit einer Solche Gewichtung zu machen. Es gibt eben kein richtig oder flasch, allerdings sollten die Resultate für die Endnutzer zufriedenstellend sein. Persönlich würde ich mir ab und zu wünsche, dass man es teilweise selber einstellen könnte und somit komplexe Anfragen mit der Eweiterte Suche vermeiden könnte. Dies ist allerdings die Sichtweise einer angehende Informationsspezialistin und somit sicher für andere Nutzer überfordernd. Bei der Einstellung der Gewichtung sollte also gut für die Endnutzer überlegt werden und womöglich Tests mit Laien auch durchgeführt werden.
Ah und zur Personalisierung nach Studium- oder Fachbereich: ich finde es speziell, dass man dies ausprobiert hat. Bei der Suche in einer Bibliothek hat man – auch im Studium – nach Fachfremde Litteratur zu suchen und man wäre mit eine solche personlaisierte Gewichtung dann sicher nicht zufrieden.
Übung zur Datenintegration
Ziel der Übung war einen Import der mit MarcEdit und OpenRefine konvertierten Daten aus Koha, ArchivesSpace, DSpace und DOAJ in VuFind zu erledigen.
Damit man frisch in VuFind starten konnten, wurde mit diesem Befehl die Testdaten als Erstes gelöscht (siehe Quelle:
/usr/local/vufind/solr.sh stop
rm -rf $VUFIND_HOME/solr/vufind/biblio/index $VUFIND_HOME/solr/vufind/biblio/spell*
/usr/local/vufind/solr.sh start
Die Daten von Koha, ArchivesSpace und DOAJ konnte ohne Schwierigkeiten importiert werden. Einzig die Daten von DSpace stellten ein Problem dar. Nämlich erwartet Solr eine ID, welche bei MARC den Feld 001 entsprechen würde. Schwierigkeit ist dabei, dass dieses Feld in Marc nicht obligatorisch ist. Dieses Feld ist bei den Dateien von DSpace nicht verfügbar, so müsste man selbst dieses Feld ertstellen, um diese importieren zu können. Dabei ist es wichtig, dass die IDs eindeutig sind, ansonsten löschen wir ein schon hochgeladenes Datensatz.
Gruppendiskussion: Perfekter Katalog
Wir hatte eine Diskussion über den perfekten Katalog in Teilgruppensitzungen. Wir waren in der Gruppe von der Frage etwas überfordert. Was für eine grosse Frage! Es ist eben schwer zu sagen, was ein perfekter Katalog sein könnte, denn dies von der Nutzung, den Kunden und den Ziele der Institution abgängig ist. Je nach Branche könnte die adäquate Form eines Katalog unterschliedlich sein. Für mich würde einerseit die Ästhetik der Suchoberfläche und den Retrieval punkten.
Quellen: mein Blog, Gaby’s Blogeintrag der letzten Sitzung, Skript, Handbuch von Solr, VuFind: Re-Indexing