5 Funktion und Aufbau von Archivsystemen (2/2) / Repository-Software für Publikationen und Forschungsdaten
Begrifflichkeiten für Übung Bedienung
Accession, Resource und Archival Objekt sind zentrale Begriffe für die archivirische Tätigkeit, besonders hier für ArchivesSpace von Bedeutung. Mit diesen hatte ich selber bei dem letzten Mal Mühe. Dank diesen Erklärungen ist es mir ein bisschen klarer geworden.
- Accession: ist die Dokumentation der Erwerbung, wegen vertraulichen Angaben oft nicht öffentlich. Wir hatten dies letztes Mal direkt auf «public» gesetzt, was man im Normalfall nicht machen würde. Erst dann, wenn wir es nach Erschliessung aller Angaben veröffentlichen möchten und keine Gründe dagegen sprechen, würden wir es auf «öffentlich» stellen. Dazu wird in einem Archiv zuerst alle Angaben zu der Erwerbung erfasst und dann die Arbeit mit Ressource angefangen.
- Resource: Man legt in ArchivesSpace eine Ressource und diese ist der Zentraler Nachweis auf der obersten Ebene der Verzeichnungsstufen. Es kann einen Nachlass oder eine Sammlung sein (kann aber auch direkt zum Objekt sein, wenn die Resource nur eine Verzeichnungsstufe hat).
- Archival Object: ist den Nachweis von Objekten auf weiteren Verzeichnungsstufen (Bestand/Fonds, Serie/Series, Akte/File, Einzelstück/Item). Sie werden als “Add Child” an vorhandene Resources gehängt, dafür muss man allerdings im Edit-Modus wechseln. Archival Object war allerdings bei uns nicht Teil der Übung.
Mit dieser Erklärung bin ich nicht sicher, ob wir – in meiner Gruppe – richtig erschlossen haben, da wir Bestand und Serie des Camenisch Nachlasses erschlossen haben. Da hat Giulia recht, nächstes Mal lieber den NYU User Manual anschauen, um Fehler zu vermeiden.
Neben dem Manual der NYU findet man «leider» online praktisch keine öffentliche Hilfestellung für ArchivesSpace. Es ist zwar eine Open-Source-Software, aber man muss Mitglied sein, um Online-Hilfe zu erhalten. Da wurde ein anderes Geschäftsmodell gewählt.
Lösung zur Übung und Aufbau Tektonik
Herr Meyer mache eine Live-Vorführung in ArchivesSpace, um aufzuzeigen wie man mit den Archival Objects umgeht, da wir dieses Element nicht Teil der Übung war. Unter dem Menu Ressource, kann man die angelegte Ressource anschauen und ein Object an dieser in dem Edit-Modus mit «Add Child» verbinden. Auch ist es möglich auf der gleichen Stufe wie einem Archival Object ein neues zu verknüpfen, dies mit «Add Sibling». Eine Besonderheit unter der Ebene Archival Object ist, dass keine ID eingegeben wird. Dieser wird automatisch erzeugt und erbt aus der Ressource.

Import und Export
ArchivesSpace ermöglicht den dateibasierten Import und Export in mehreren Formaten (EAD, MARCXML, CSV) und bietet dazu auch eine OAI-PMH-Schnittstelle. Mit zwei Übungen haben wir EAD-Beispieldaten in ASpace importiert und diese dann in MARCXML exportiert.
Übung Import
Aus den Beispieldaten hatten wir in der Gruppe die «The American Association of Industrial Editors (AAIE) Records» ausgewählt und diese als «raw XML file» lokal gespeichert. Dann wurden diese Records in ArchivesSpace importiert (unter Create > Background Job > Import Data). Zuerst hatte ich für den Import den falschen Format ausgewählt.
Den Fehler habe ich dann dank der Gruppe verstanden und erneut den Import probiert. Bei diesem zweiten Versuch ist den Import reibungslos verlaufen. Zusammen haben wir noch die Beispieldatei in «raw XML» mit den Import verglichen. Wir fanden auf der Schnelle keine grosse Unterschiede, aber bemerkten dass die Ansicht in HTML angenhmer zu lesen und zum Browsen ist.
Übung Export
Als zweite Übung haben wir den importierte Beispieldatei im Format MARCXML exportiert und lokal gespeichert. Die Exportfunktion befindet sich in der Button-Leiste bei der «Ressourcen». Den Resultat dieser Export musste wir vergleichen und vor allem schauen ob dieser verlustfrei oder nicht ist. In unserem Gruppe bemerkten wir wiederrum keine Unterschiede. Allerdings haben wir nicht ganz im Detail verglichen können. Wichitg trotzdem zu wissen: Ein Export ist in der Regel nie komplett verlustfrei.
Nachtrag: Auf unseren Feedback antwortete Herr Lohmeier nach der Diskussion (siehe unten) und lass uns wissen, dass es gut möglich sei, dass es bei dieser Beispieldatei tatsächlich keine Verlüste gibt. Dies liegt aber davon, dass die AAIE-Datei nicht sehr viele Informationen beinhaltet und nicht sehr viele Verzeichnungsstufen ausfweist. Den Unterschied wird deutlicher, wenn eine Ressource mit viel Information und viele Verzeichnungsstufen exportiert wird. (Nur ein Teil wird in MARCXML exportiert).
Diskussion zu den Übungen
Die Gruppen hatten zum Teil Probleme, sowohl beim Import als auch beim Export. Dies liegt an EAD und ist eine Schwäche davon. Nach Herr Lohmeier – was mich nach der Diskussion überrascht hat – sei EAD der beste Ausstauschformat, der es aktuell gibt. Diesen Austauschformat ist weit verbreitet, aber trotzdem entstehen oft Probleme und Fehlermeldungen. Zum Beispiel landen Informationen an anderen Stellen oder es gibt Fehlermeldungen wegen Zeichnenzahl (und Teil der Information wird gelöscht). So haben wir gelernt, dass es funktionniert nicht ganz so einfach mit den Ausstauschformate, wie man sich das wünschen würde.
Noch einen Hinweis: Den Export in MARCXML kann nicht verlustfrei sein, oder mindestens nicht aus einem Wurf, da MARCXML Medienzentriert ist und eine Ressource beschreibt. Hingegen in EAD hat man mehere Ressourcen. => Also: Wenn ich in EAD mehere Verzeichnungsstufen nach ISAD(G) habe, wie kann ich das in MARCXML exportieren? Wie viele Verzeichnungsstufen könnte man überhaupt in MARCXML kriegen? Eine Option wäre mehrere MARCXML zu exportieren. In ArchivesSpace wird allerdings nur die Hauptressource in so einem Fall exportiert. Somit werden XML-Dateien beim import «flachkelopft», wie es Herr Lohmeier so schön beschreibt.
Als Kontrolle eines Export können die Mappingtabellen, welche ArchivesSpace zu Verfügung stellt, dienen. Damit erhält man einen Einblick, was in ArchivesSpace bei dem Export passiert bzw. welches Feld wiird in welchem konvertiert.
Marktüberblick Archivsysteme
- ArchivesSpace mit grosse Community in der USA
- Access to Memory (AtoM), welcher uns Karin ein Einblick gab.
- In der Schweiz werden vorwiegend scope.Archiv und CMISTAR benutzt. Die Klasse machte dazu auf ANTON, den neuen Archivsystem aus der Schweiz.
Unterschiede zwischen Bibliotheks- und Archivsystemen
Wichtige Unterschiede gibt es zwischen Bibliotheks- und Archivsysteme, die Meisten wurden schon über den letzten Vorlesungstage erwähnt. Bibliotheken sind konzentriert auf die Erschliessung eines Mediums und auf Angebote und Vermittlung für Benutzerinnen. Auch sind die benutzten Software medienzentriert und somit werden andere Metadatenformate benutzt; aktuell hat sich MARC21 durchgesetzt, aber vielleicht wird irgendwann BIBFRAME benutzt. Archive interessieren sich mehr für den Entstehungszusammenhang von Bestände, welche meist unikal sind und auf Anfrage benutzt werden. Die Software orientieren sich an anlogen Objekte und als Metadatenformat wird EAD verwendet, später vermutlich Records in Context (RiC).
Repository-Software für Publikationen und Forschungsdaten
Open Access und Open Data
- «Open Source» sind Offene Quellendaten (für Software), dieses Term haben wird viel im Modul benutzt.
- «Open Access» wird mit Publikationen verknupft
- Dagegen «Open Data» für die Veröffentlichung von Forschungsdaten. Daraus hat sich den Begriff «Open-Access-Repositorien» entwickelt. Heute versucht man immer mehr die Forschungsdaten zu veröffentlichen, was auch einen Wandel in der Gesellschaft zeichnet. Es gibt dafür auch Forschungsinformationssysteme, sogenannte «CRIS» = Current Research Information System.
mit DSpace hat man die Möglichkeit mit Forschungsdaten sowie auch Publikationen zu arbeiten.
Forschungsinformationen
- Zenodo ist einen Repositorium vom Cern betrieben und ist konstenfrei. Da werden Forschungsdaten und Publikationen publiziert. Gilt hier als “Best Practice”. Wurde mit der Software Invenio gebaut.
- TORE als Repositorium für Forschungspublikationen und Forschungsdaten von der Technische Universität Hamburg (TUHH).
Kleiner Exkurs mit Orchid: Kein Forschungsinformationsystem. Besonders ist die Personen-IDs, welche vergeben werden. Jeder kann sich anmelden, seine Informationen eintragen und ändern. Damit werden alle eindeutig identifiziert und ermöglicht die Personen mit gleichen Namen zu unterscheiden.
DSpace
Die Software ist für Publikationen und Forschungsdaten geeignet. Für Forschungsdaten gibt es eine Eweiterung namens DSpace-CRIS. Das Standard Qualified Dublin Core (eine Erweiterung von Dublin Core) wird verwendet, aber die Software kann auch mit DataCite betrieben werden. Von Data Cite habe ich bischer noch nie gehört, also verfolgte ich den angegebenen Link der Dozenten. Es handelt sich um einem Schema mit einer Liste von metadata properties für die präsize und konsitente Identifikation einer Ressource, dies für Retrieval und Zitation. Dieses Schema dient somit die Beschreibung von Daten und hat sich inzwischen als weltweit eingesetztes Modell etabliert (Forschungsdaten.info. DataCite selber ist eine Registrierungsagentur von DOIs für Forschungsdaten. DSpace 6.x wurde 2016 veröffentlich, immer noch gepflegt, aber seit längerem nicht mehr weiterentwickelt, da DSpace 7.x ist 2020 veröffentlicht werden sollte. Da wir es ein Technologiebruch geben: neue Technologien im Frontend mit Angular und eine Programmierschnittsstelle im Backend mit neue REST API. Wichtig zu wissen ist, dass es mit der neuen Version keine Erweiterung (DSpace-Cris) für Forschungsdaten mehr brauchen wird.
DSpace hat so wie Koha auch eine OAI-PMH-Schnittstelle, die erlaubt extern Metadaten von DSpace aufzurufen. Dazu ermöglicht die Schnittstelle SWORD in DSpace die Publikaton auf anderen Webseiten.
Übung
Um DSpace auszuprobieren nutzen wir aus Zeitgründen nur die Demo. Wir haben uns angemeldet, eine Community und darin eine Collection erstellen, sowie ein Dokument in der Collection hochgeladen. Leider hatten wir Probleme mit der Anmeldung, aber die Dozenten fanden eine Lösung dazu: anstatt sich als Site Administrator anzumelden, meldeten wir uns als Community Administrator an. Diese Rolle hat nicht alle Berechtigungen. Für die «Sample Community» aber schon und mit der Erstellung einer Sub-Community hat es dann geklappt.
Marktüberblick Repository-Software
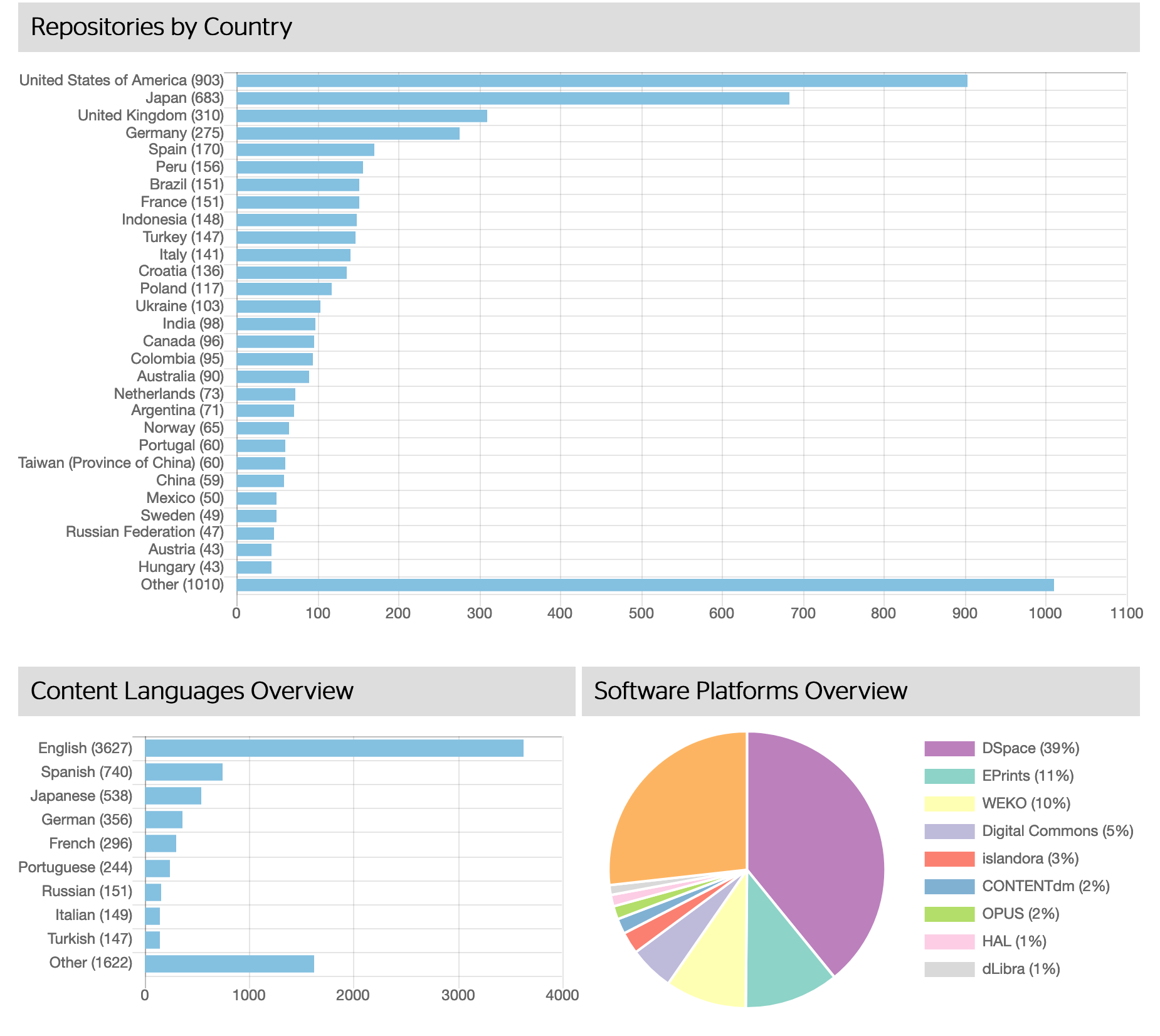
Wir schauten uns dazu gemeinsam die welweit meistbenutzten Repository-Software. Hier lässt sich gut zeigen, wieso DSpace von den Dozenten ausgewählt wurde. Dazu lernten wir dass die meist Open-Acess-Repositories-Software – passend zu der Bewegung – Open Source sind. In der Schweiz sieht es allerdings anders auch, da ist Invenio führend und von Eprints gefolgt. Zum Schluss sind relevante (Open Source) Systeme in D/A/CH: Eprints, Fedora / Islandora, Invenio, MyCoRe und OPUS.
Quellen: Giulia’s Blog, DataCite, Forschungsdaten.info, Skript