6 Tag Metadaten modellieren und Schnittstellen nutzen 1/2
Schaubild
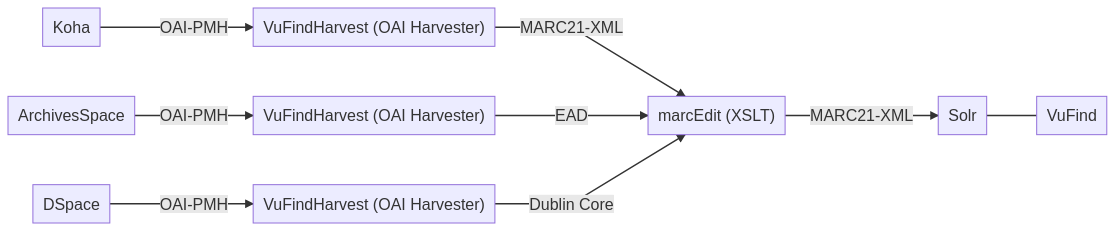
Den Schaubild vom Tag 1 wurde überarbeitet. Damals wurde geplant mit dem OAI Harverster metha zu arbeiten, aber da funktionniert das «Ernten» nicht ganz einwandfrei und deswegen wurde von den Dozenten stattdessen VuFindHarvest ausgewählt. Letzeres ist Teil von VuFind, kann aber eigenständig verwendet werden. Bis jetzt haben wird die drei Systeme aus diesem Schaubild kennengelernt: Koha, ArchivesSpace und DSpace und gelernt, dass alle Systeme eine OAI-PHM Schnittstelle haben. Mit diesen haben wir in dieser Lektion Dateien in drei verschiedene Formate (MARCXML, EAD und Dublin Core) heruntergeladen. Mit MarcEdit werden wir über einen Crosswalk die Dateien in MARC21-XML umwandeln. Solr ist Teil der VuFind Software und ist eine Volltextsuchmaschine, welche von vielen Webanwendungen benutzt wird. Solr ist keine Archiv- oder Bibliotheksspezifische Software. Sie wird in sehr vielen Websiten benutzt – z.B. von Netflix und Amazon – und ist eine der bekannteste Suchmaschine neben Elasticsearch. Ich bin gespannt über diese mehr kennenzulernen, da wir bis jetzt vor allem spezifische Anwendungen benutzt haben.
Metadaten modellieren und Schnittstellen nutzen (1/2)
Schnittstellen SRU, OAI-PMH und Z39.50
Es gibt sehr viele Übertragungsprotokolle in der Bibliotheks- und Archivswelt. Davon sind drei besonders wichtig: Z39.50 von der Library of Congress, SRU (Search/Retrieve via URL) auch von der Library of Congress und OAI-PMH – Open Archives Initiative Protocol for Metadata Harversting) von Open Archives Initiative. SRU und OAI-PHM sind nicht mehr so neu, aber die Nutzung ist sehr vebreitet und sind somit etablierte Protokolle. SRU und OAI-PMH sind aber doch neu genug, um das Internet «gut zu kennen» und sind über internetadressen abrufbar. So kann man diese im Browser nutzen und bekommt doch eine Rückmeldung. Z39.50 aber noch älter: wurde in 1984 entwickelt und wird seit 1990 von der Library of Congress fortgeführt (Wikipedia). Z39.50 ist allerdings nicht möglich über einen Browser zu nutzten, sondern man benötigt dafür eine Software, welche über einen speziellen Port mit den Server kommuniziert. (So wie ich es wahrnehme, schauen wir Z39.50 vor allem an, weil dieser Protokoll historisch prägnant ist).
Metadaten über OAI-PMH harvesten mit VuFindHarvest
Im Englischen wir der Fachbegriff «harvesting» für das «Ernten» von Daten verwendet. Es trifft ja eigentlich auch sehr gut zu, da den Ziel dieser Praxis ist über Schnittstellen Daten abzugrasen oder alles zu erhalten, was eine Schnittstelle hergibt. Wir verwendeten dafür VuFindHarvest, ein OAI Harverster aus dem VuFind-Projekt, welcher nur über OAI-PMH Schnittstellen Daten ziehen kann. Als erstes galt es zu überprüfen, ob die OAI-PMH-Endpoints von Koha und ArchivsSpace abrufbar sind und ob die Daten von der Demo von DSpace noch verfügbar sind. (Achtung: nicht vergessen ArchivesSpace wieder zu starten!) (Ich hatte ArchivesSpace schon gestartet. Koha haben wir schon installiert und die Daten sind gespeichert – hier das Einzige, was evtl. passieren könnte, ist da man sich nicht anmelden kann.)
Die Übung
Nach der erwähnte Kontrolle wurde VuFindHarvest mit folgenden Befehle in der Kommandozeile installiert (bzw. zuerst alles aktualisiert, den composer, php und php-xml installiert, dann Ordner wechselt, den Packet von GitHub herunterladen, in dem heruntergeladenen Ordner wechelt und schlussendlich die Software mit composer installiert):
sudo apt update
sudo apt install composer php php-xml
cd ~
wget https://github.com/vufind-org/vufindharvest/archive/v4.0.1.zip
unzip v4.0.1.zip
cd vufindharvest-4.0.1
composer install
So sahen die Befehle für das Harvesting (statt my_target_dir kommt noch den ausgewählten Ordner der Ergebnisse oder wie man einen Ordner für die Ergebnisse nennen möchte – denn die automatische Erstellung vom einem Ordner an diesem Punkt zum tollen Service von VuFindHarvest gehört! Ich nannte das Ordner harvest_data):
-
für Koha
cd ~/vufindharvest-4.0.1 php bin/harvest_oai.php --url=http://bibliothek.meine-schule.org/cgi-bin/koha/oai.pl --metadataPrefix=marcxml my_target_dir -
für ArchivesSpace
cd ~/vufindharvest-4.0.1 php bin/harvest_oai.php --url=http://localhost:8082/ --metadataPrefix=oai_ead my_target_dir -
und für DSpace
cd ~/vufindharvest-4.0.1 php bin/harvest_oai.php --url=http://demo.dspace.org/oai/request/ --set=com_10673_1 --metadataPrefix=oai_dc my_target_dir
Das Harvesting hatte mit ArchiveSpace und Koha geklappt, bei DSpace bekamm ich die Fehlermeldung Service Unavailable und den Harvesting endete nie.
Ich fragte im geimeinsamen Dokument, was ich falsch gemacht habe. Na ja, ganz einfach vergessen den Set im Befehlt zu nehmen. Hätte ich nur in der README.md geschaut! :)
Das Parameter wird mit --set= und dem Set-ID angeben. In unserem Fall: --set=com_10673_. Im oberen Befehl habe ich dies angepasst. Mit dieser Anpassung hat es gut gepasst!
Hier die partielle Auflistung der Ergebnisse im Terminal:
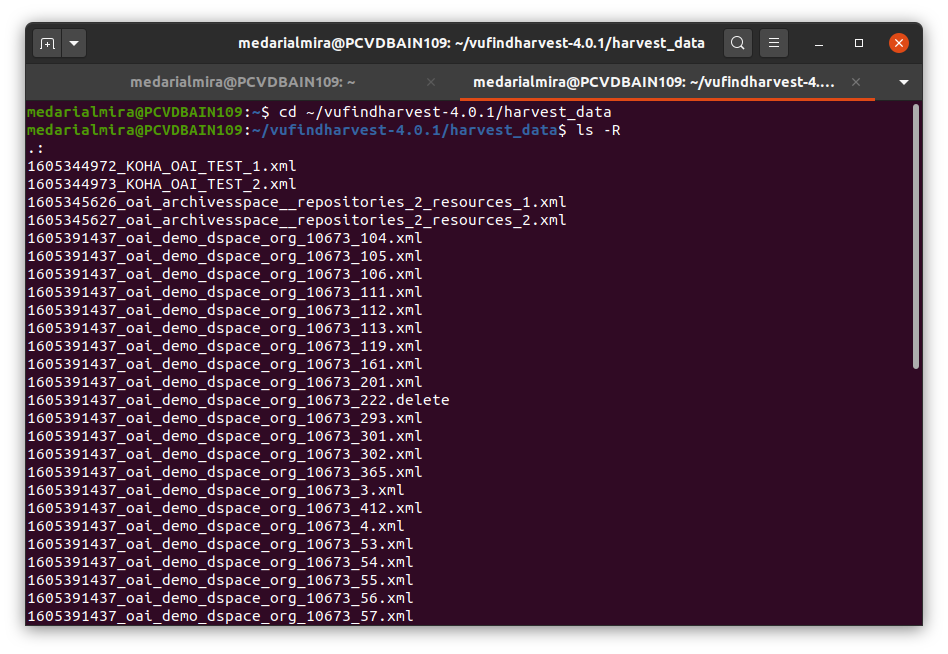
Note zu der OAI-PMH Schnittstelle und Unterschied zu den vorherigen Exports: bis jetzt haben wir immer Dateien über die Administration expotiert. Wenn wir aber keinen zugriff auf einem System haben, können wir über die OAI-PMH Schnittstelle totzdem auf öffentliche Dateien zugreifen und diese herunterladen.
Crosswalks & XSLT
In der Übung haben wir den Harvest in mehere Formate erledigt. Mit dem Begriff Crosswalks geht es um die Konvertierung von einem Metadatenstandard in einen anderen zu beachreiben (z.B. MARC21 in Dublin Core). XSLT ist eine Programiersprache zur Transformation von XML-Dokumenten (W3C Empfehlung, 1999). > Litteraturempfehlung auf den Folien, da wir werden dies nicht benutzen, weil die Zeit nicht reicht.
MarcEdit7
MarcEdit ist eine kostenlos nutzbare Software, aber nicht Open Source (zu Errinerung heisst es: den Quellencode steht nicht zur Verfügung). Die Software hat schon mehere Versionen hinter sich und ermöglicht Marc-Daten zu bearbeiten. Für die Arbeit mit MARC21 ist sie die meistgenutzte Zusatzsoftware.
Hier eine Empfehlung der Dozenten diese auf dem eigenen Rechner zu installieren, da wir die Software vielleicht selber mal brauchen könnten. Die Software ist auf Windows, Linux, aber auch auf Mac installierbar.
Die Übung
Nach der Installation und Configuration von MarcEdit haben wir eine Übung gemacht, wo es darum ging Crosswalks anzuweden bzw. Dateien umzuwandeln. Ziel war die Daten aus ArchivesSpace (EAD) und aus DSpace (DC) nach MARC21XML zu konvertieren. Als Hilfe kann die Anleitung für “XML Conversion” mit MarcEdit von der Unibibliothek aus Illinois benutzt werden.
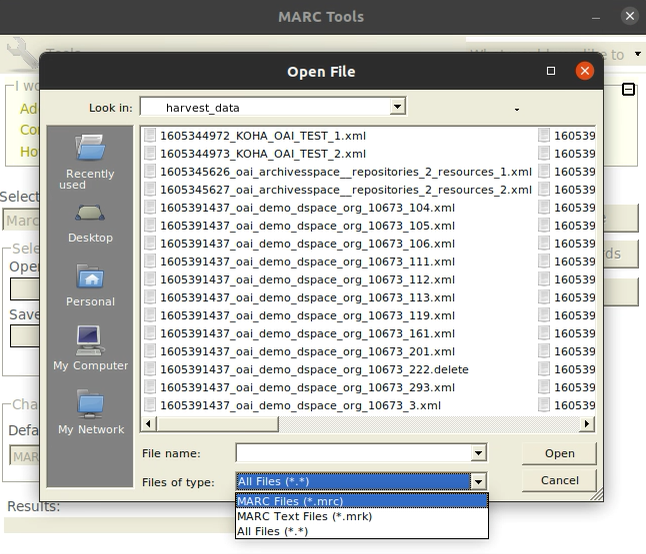
Meine Meinung dazu? Na ja, die Konvertierung war sehr anstrengend. Die von DSpace und ArchiveSpace waren im Marc Edit gar nicht auffindbar, obwohl ich es mit allen Funktionen probierte. Ich fragte den Dozenten nach und bekamm eine Antwort: wenn nach den Daten zur Konvertierung gesucht wird, müssen alle Formate bei der Auswahl des Dateityps ausgewählt werden (siehe Bild). Für ArchivesSpace ging es dann auf Anhieb. Mit DSpace probierte ich es mehermals mit der Funktion OAIDC > MARCXML, lieferte mir aber immer leere Dateien als Resultat, bis ich es gemeinsam mit den Dozenten probierte und es dann tatsächlich funktionnierte (wenn ich Save As...wählte, hatte ich auch da nicht daran gedacht den Dateityp anzupassen).
Quellen: Skript, Solr, Wikipedia Z39.50, VuFindHarvest, README.md VuFindHarvest