10 Linked Data
Aktuelle Datenmodelle für Metadaten
- BIBFRAME
- Records in Context (RiC)
Beide sind neue Modelle von Metadatenformate; BIBFRAME aus dem Bibliotheksbereich und RiC aus dem archivischen Bereich. Seit einige Jahren zeigt sich den Weg dorthin zu gehen, also wichtig diese Entwicklungen für unsere Zukunft in den Informationswissenschaften zu kennen.
BIBFRAME
BIBFRAME ist einerseits den Name einer bibliothekarischen Initiative, anderseits auch einen Format. BIBFRAME wird seit 20212 von der Library of Congress entwickelt, um MARC21 abzulösen. Ziel war MARC21 (und MODS – eine vereinfachte Form von MARC21) zu modernisieren und die Semantic Web und Linked Data Trends gerecht zu werden. Aktuell wird BIBFRAME 2.0 verwendet. BIBFRAME basiert auf FRBR (Functional Requirements for Bibliographic Records) und auf RDA (Resource Description Acess) als Regelwerk – Begriffe, welche uns im Studium schon mehrmals begegnet sind. FRBR ist zu BIBFRAME, was CIDOC CRM für LIDO ist (Hier zu Erinnerung). Also einem Konzept, welcher angibt, was beschrieben werden muss und BIBFRAME ist der eigentlichen Format. Allerdings wird als Kritik argumentiert, dass BIBFRAME zwar auf FRBR und RDA basiert, aber beide nicht vollständig umsetzt. Der Dozent (Herr Meyer) findet, dass es aus guten Gründen so vereinfacht aufgebaut wurde. Auch wie LIDO folgt BIBFRAME den Linked Data Paradigmen: Objekte über URI eindeutig identifizierbar und es werden definierten Vocabulare verwendet.
BIBFRAME besteht dazu aus dem BIBFRAME Model als Datenmodell und den BIBFRAME Vocabulary. Wesentlichen Unterschied zu MARC21 und anderen bibliographischen Formate ist das Datenmodell und die Beschreibung in drei Ebenen: Work, Instance und Item. Work als intellektuelle Idee eines Werkes, Instance als Ausgabe des Werkes und Item als Exemplar. In anderen bibliographischen Formate werden diese nicht so streng getrennt, sondern in einem Datensatz beschrieben. Die Ebenen werden dazu mit Entitäten beschrieben, dies mit Agent (Akteure des Werkes), Subject (z.B. behandelte Themen) und Event (Ereignis als Inhalt des Werkes wie z.B. eine Transkription eines Interviews). So werden aber auch nicht immer alle Entitäten verwendet, sonder nur die, die eine Beschreibung dienen können. Um eiheintliche Begrifflichkeiten für die Beschreibung zu verwenden, sind im Vokabular Konzepte und deren Eigenschaften definiert. Diese Ontologie umfasst Beschreibungsklassen (Class) wie einen Autor und ihre jeweiligen Eigenschaften (Property) – in Fall einem Autor z.B. den Geburtstagsdatum – , welche sich auch mit den MARC Fields und Subfields vergleichen lassen. Im Unterschied zu MARC sind diese Klassen und Eigenschaften teilweise hierarisch strukturiert. Zum Beispiel sind Autor und Verleger Unterklassen von «Beiträger». Dies kann sehr hilfreich sein, da wir dann eine Suche über alle Beiträger und alle seine Unterklassen erledigen kann.
Dank die vielseitige Beziehungen zwischen Objekten, wird mit BIBFRAME mehr beschrieben und somit ermöglicht der Format nicht nur nach Records zu suchen, sondern auch nach Relationen.
Hier noch das Modell als Visualisierung von der Library of Congress: in Blau die drei Ebenen mit der hierarische Beziehung, in Orange die Entitäten und in Grau klassische Metadaten als Beispiel.
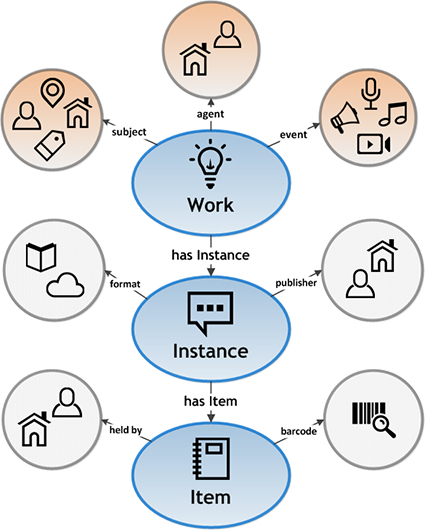
Unterscheiden tun sich MARC und BIBFRAME schlussendlich indem, dass in MARC alle Beschreibungen zu einem Object sich in einem Datensatz ohne Beziehungen zu anderen befinden. So kann einem Record als geschlossene Einheit einfach verstanden werden, aber dieses System stosst an seinen Grenzen, wenn es um Datenmanagement gehen soll. In BIBFRAME sind nicht alle Beschreibungen zu einem Objekt in einem einzelnen Datensatz, sondern durch eine Reihe von Datensätze, die in Relation zueinander stehen. So muss nicht eine Information mehrfach abgelegt werden und mehr Kontext als bei MARC wird lesbar.
Records in Context (RiC)
Ähnlich wie BIBFRAME ist RiC im archivischen Kontext und basiert auch auf Linked-Data-Prinzipien. Ziel ist es mehrfache Relationen zwischen Entitäten herzustellen. In der Schweiz arbeitet die Projektgruppe ENSEMEN an einer schweizerischen Ausprägung von Records in Context. Herr Stettler ist daran beteiligt. Vielleicht erzählt er uns mal ein bisschen mehr darüber, das wäre doch spannend! Auch hier gibt es eine Ontologie, aber noch in Bearbeitung. Im archivischen Bereich geht es anscheinend nach Herr Lohmeier länger, da gundsätzliche Punkte diskutiert werden, um was dauerhaftes zu schaffen. Würde mich interessieren, welche? Mit MARC21 gibt es eine festere Standardisierung, was es nicht im Archivbereich so gibt. Man hat eine andere Aufgangssituation: ISAD(G) hat sich mit seiner technische Ausprägung EAD durchgesetzt, aber andere Standards – ISAAR (CPF), ISDF und ISDIAH – sind nie richtig zur Anwendung gekommen. Viele warten auch auf etwas Neues und mit RiC könnte es tatsächlich zu einer echten Veränderung kommen. Für die Konvertierung gibt es die Open-Source-Software RiC-O Converter. Auch arbeitet docuteam an Prototypen für RiC-konforme Erschliessungs- und Katalogisiersoftware, dies in Collaboration mit Zazuko und Artefactual (das Unternehmen hinter der Software AtoM( * )): https://ica-egad.github.io/RiC-O/projects-and-tools.html
Um sich vertieft mit RiC auseinanderzusetzten, emfpfiehlt uns Herr Lohmeier:
- dieses Einführungsartikel von David Gniffke: Semantic Web und Records in Contexts (RiC)
- und die Präsentation von Florence Clavaud
- sowie einen anderen schweizerischen Projekt namens Archival Linked Open Data (aLOD) anzuschauen.
( * ) Kleiner Verweis zum Blogeintrag von Karin, welcher sehr gut die Open-Source-Software AtoM beschreibt.
Praxisberichte
Alma
Folgend zu der Theorie lass uns Sandra Live einen Blick auf Alma werfen. Ich werde vermutlich nicht damit arbeitet, da ich eher an dem archivischen Bereich interessiert bin, aber fand dieses Einblick sehr interessant. Seit Anfang des Studiums habe ich nur durch den Modul STAN ein wenig mit Aleph erschliessen können. Im Vergleich zu Aleph sieht immerhin Alma deutlich moderner aus, was ich sehr efreulich finde. Auch finde ich interessant, dass Datensätze von anderen Bibliotheken angeschaut werden können.
Online-Katalog für das Deutsche Literaturarchiv Marbach
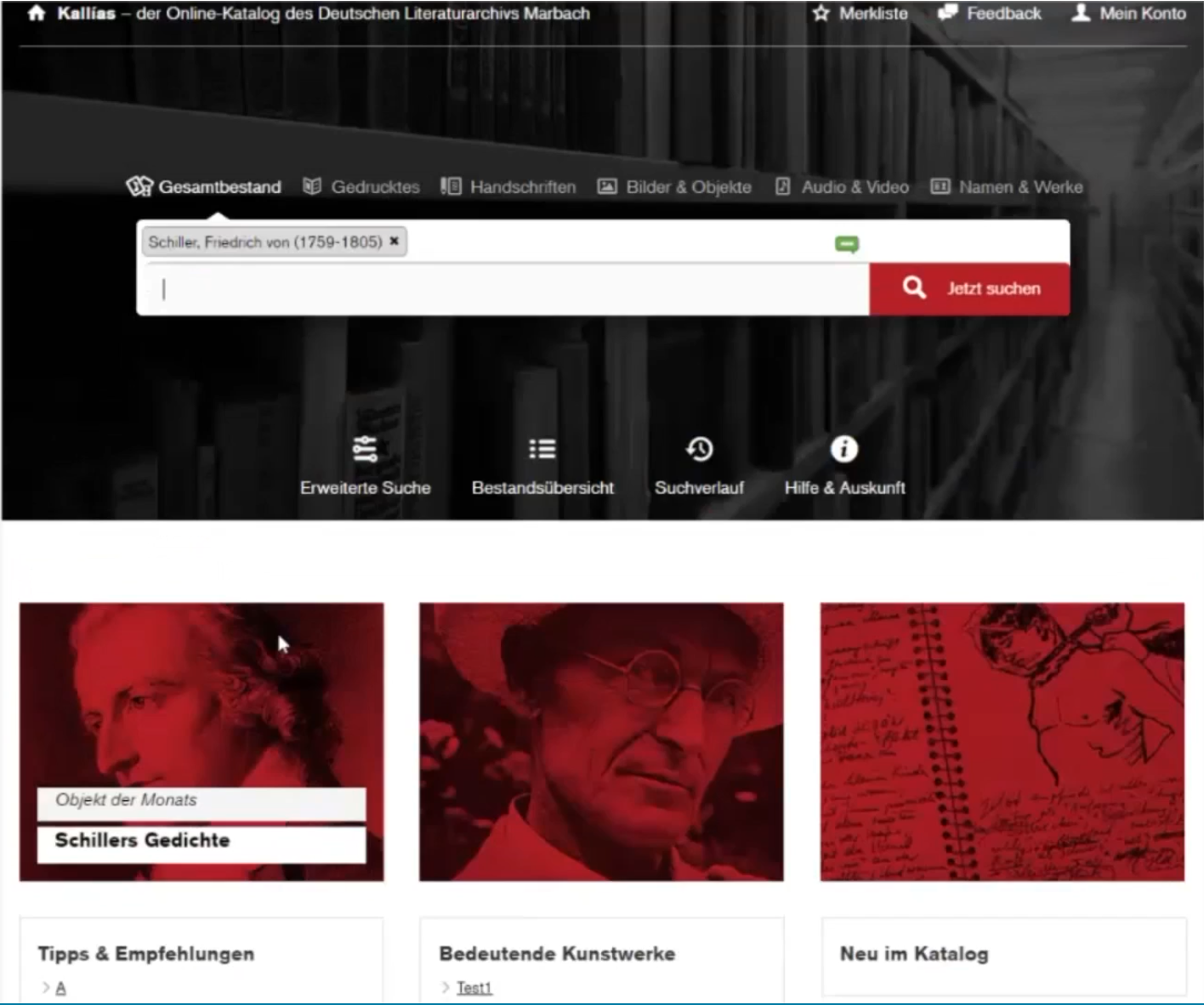
Am Ende der Vorlesung erzählten uns die Dozenten über das Projekt für das Literaturarchiv Marbach. Sie sind dran einen neuen Katalog zu entwickeln, welcher Objekte aus einem Archiv, einer Bibliothek und einem Museum verbindet. Derakuteller Katalog ist nicht besonders nutzerfreundlich, da es nicht möglich ist nach allen arten von Objekten gleichzeitig zu suchen. Dies macht es für Nutzer sehr umständlich. Es war sehr beeindruckend zu sehen, wie die Dozente es geschafft haben, das Problem zu lösen und damit auch eine optisch attraktivere Oberfläche zu gestalten.
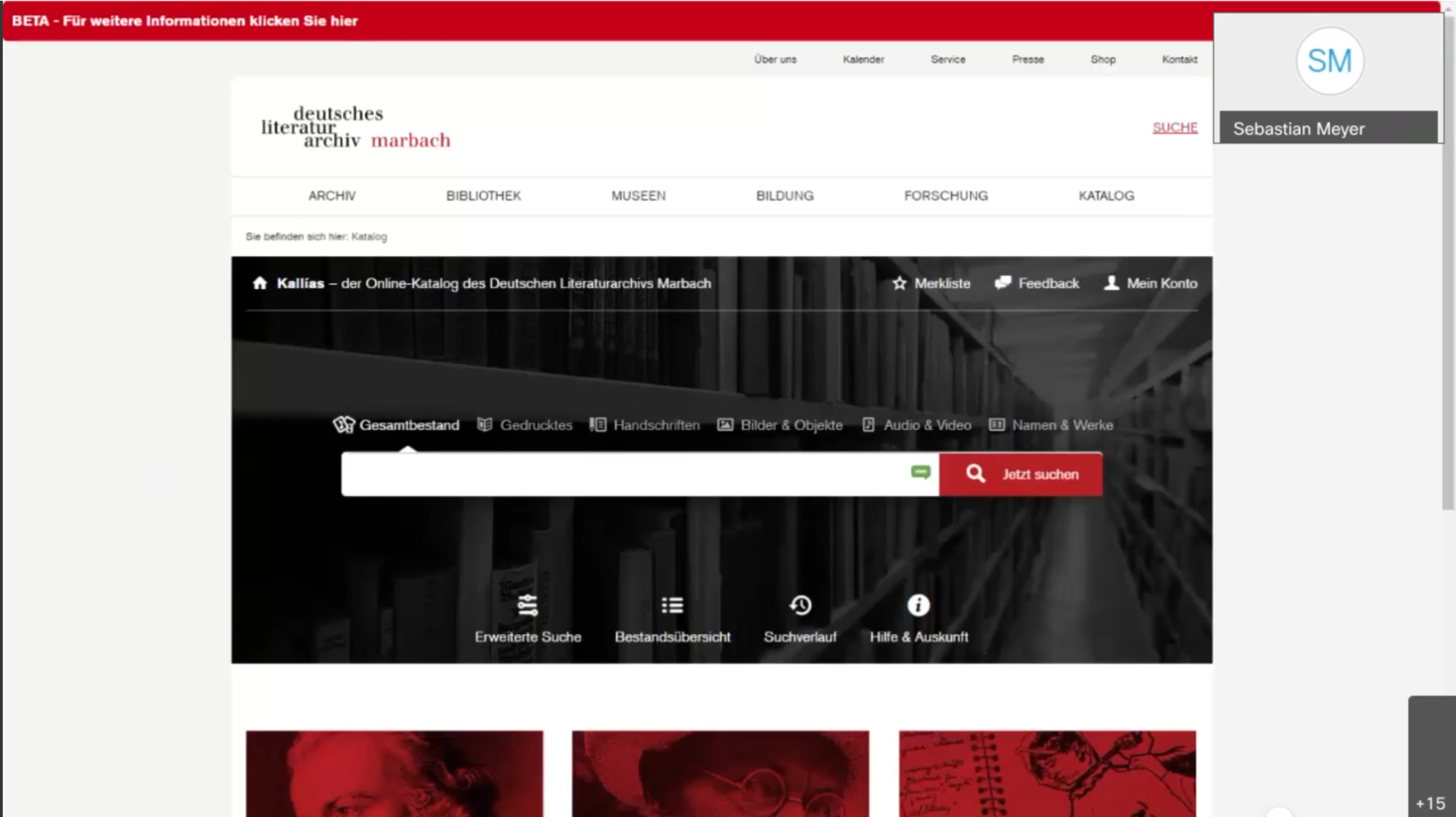
Und einen Einblick in der Suche des neuen Online-Katalog in der Beta-Version:
Quellen: LIDO am Tag 8, BIBFRAME-Modell von der LOC, ENSEMEN, RiC-O Converter, RiC-O Projekte, Semantic Web und Records in Contexts (RiC), Präsentation von Florence Clavaud, Archival Linked Open Data (aLOD), Blogeintrag von Karin zu AtoM und Projekt für das Literaturarchiv Marbach.