8 Suchmaschinen und Discovery-Systeme Teil 1
Nachtrag zu Metadaten modellieren und Schnittstellen nutzen
Diskussion der Aufgabe zur Anreicherung
Zu dem Zeitpunkt wurde die Anreicherungsaufgabe in OpenRefine besprochen. Darüber werde ich hier nicht berichten, aber möchte auf meinen Blogeintrag verweisen, in welcher ich ein kurzes Kommentar zu meine Fehler noch eingegeben habe.
Validierung von XML
- Wir exportieren das Gesamtergebnis als XML in ein neues Verzeichnis.
Wenn man ein sauberes XML machen möchte, muss man es mit einem XML-Schema abgleichen z.B. mit dem MARC21-Schema der Library of Congress. Man kann mit dem Schema von der Library of Congress nicht unbedingt die Inhalte verifizieren, aber zumindest die Form. Die Validierung ist eine wichtige Grundlage. Diese Validierung wird vom Dozent an dem Beispiel der XML Datei mit den DOAJ-Daten aus Open Refine, welche wir zusammen exportiert haben.
- Für die Validierung können Sie das Programm
xmllintverwenden, das unter Ubuntu vorinstalliert ist. - Zum Abgleich gegen das offizielle Schema von MARC21 laden wir dieses (XSD) zunächst herunter.
Hier ein Beispiel, wie man diesem Programm nutzen kann, um die Datei zu validieren:
wget https://www.loc.gov/standards/marcxml/schema/MARC21slim.xsd
xmllint *.xml --noout --schema MARC21slim.xsd
- Einerseits wird mit dem ersten Kommando anhand wget den Schema von der Library of Congress als Datei heruntergeladen. Hier ist es wichtig darauf zu achten, dass die Datei am gleichen Ort wie unsere DOAJ-Datei gespeichert wird. Hierfür hat Her Lohmeier den Ordner Downloads aufgewählt und somit diesen Befehl in der Shell eingegeben:
cd Downloads - Dann den zweiten Befehl eingegeben, wobei hier statt “.xml”* den DOAJ-Dateiname eigegeben wird. Damit läuft die Validierung nur über die XML-Datei, welche wir auswählen, und nicht über alle XML-Dateaien. Den –noout-Befehl ist dafür da, dass den Inhalt der Datei nicht in der Shell ausgegeben wird (wir wollen ja nur eine Validierung). Zum Schluss den Befehl –schema und darauf folgend den Dateiname des Library of Congress Schemas, welches wir heruntergeladen haben.
xmllint *.xml --noout --schema MARC21slim.xsd
Schade! Es kommen einige Fehler, somit haben wir mit der DOAJ-Datei kein valides XML erzeugt. Das heisst, dass wir jetzt nach dem Fehler in einem Editor suchen müssen.
Immerhin hat es den Vorteil, dass es uns aufzeigt, dass die Valisierung eine sinnvolle Sache ist. :)
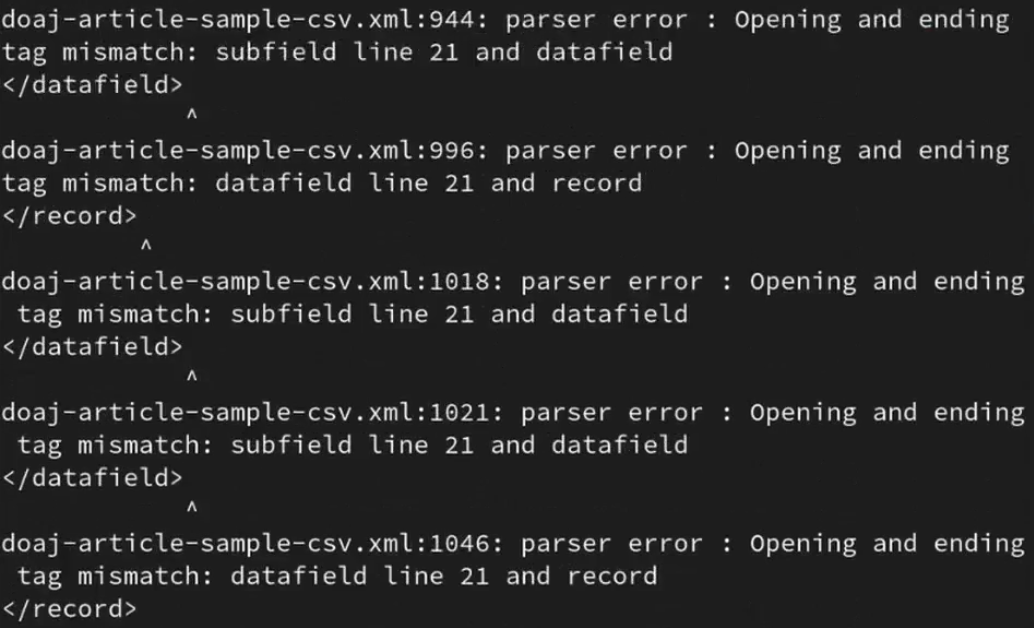
Es scheint, dass den Feld 260 b nicht geschlossen worden ist: es fehlt das schliessendes Subfield </subfield>. Das liegt sehr wahrscheinlich am Template und wurde dann korrigiert.

Exkurs: XML-Deklaration
Eine XML-Deklaration (wie eigentlich auch jede Deklaration, wie z.B. in einem XML-File) dient dazu, einen Programm den Format unsere Datei mitzuteilen. In diesem Fall, dass es sich bei einer Datei, um XML handelt. Dafür wird am Anfang der Datei wie folgt deklariert:
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
- Hier handelt es sich um einer XML-Datei der Version 1.0. mit der Zeichencodierung im Standard Unicode.
- Auch entählt die Datei eine Dokumenttypdefinition (DTD). Das ist so in etwa ein Metadaten-Schema, welches aber nicht separat sondern im Dokument liegt und Auskunft über die Form der Datei gibt. Dies wird nach dem Element standalone definiert: entweder mit dem Wert yes (in der Datei enthalten), no (es gibt ein Schema, aber liegt ausserhalb der Datei) oder (leer/weg)gelassen (heisst, das kein Schema beigelegt ist und die Datei an dem XML-Standard orientiert).
Was man sich merken sollte:
- Die Versionangabe ist pflicht, die Encoding-Angaben gehörten zur guten Praxis. Das leztes Element wird allerginds selten gebraucht.
- die Reihenfolge der Elemente einer Deklaration ist festgelegt.
Weitere Tools zur Metadatentransformation
Zur Motivation
Metadaten-Management in der Praxis, hier beim Leibniz-Informationszentrum Wirtschaft (ZBW) in Hamburg:
- Infoseite: https://www.zbw.eu/de/ueber-uns/arbeitsschwerpunkte/metadaten/
- Videointerview mit Kirsten Jeude: https://www.youtube.com/watch?v=YwbRTDvt_sA
Wir dürfen gerne das Interviews mit Kirsten Jeude anschauen, fall wir wissen wollen, wie das in der Praxis ist und auch wenn wir beruflich eventuell mit Metadaten arbeiten möchten.
Vergleich mit anderen Tools
Herr Lohmeier gibt zu OpenRefine und Alternative ein kurzer Überblick und Emfehlungen. Nach ihm eignet sich für den Anfang OpenRefine sehr gut. Wenn OpenRefine für uns zu generisch wäre und man sich zusäztlich mit Programieren - also ohne graphische Oberfläche - ausseinandersetzten wollte, dann kann man auf Alternative zugreifen. Catmandu benutzt Perl, eine etwa veraltete Programmiersprache - und eine slebstentwickelte Skriptsprache (Fix). Diese Software ist zu empfehlen, wenn man sich mit dem Thema tiefer auseinandersetzen möchte. Metafacture arbeitet daran Fix zu implementieren.
- Merkmale von OpenRefine:
- grafische Oberfläche: Transformationsergebnisse werden direkt sichtbar
- Skriptsprachen (GREL, Jython, Clojure) für komplexe Transformationen
- Schwerpunkt auf Datenanreicherung (Reconciliation)
- Alternative Software:
- Catmandu (Perl)
- Metafacture (Java)
- MarcEdit (für MARC21)
- Siehe auch: Prof. Magnus Pfeffer (2016): Open Source Software zur Verarbeitung und Analyse von Metadaten. Präsentation auf dem 6. Bibliothekskongress.
Note:
- Generell gilt, dass die passende Software anhand des Anwendungsfalls gewählt werden sollte.
- In der Praxis wird oft die Software verwendet, die schon gut beherrscht wird. Das macht es manchmal sehr umständlich.
Nutzung von JSON-APIs
Wir haben verschiedene Schnittstellen angeschaut, allerdings sehr bibliothek-/archivspezifisch: SRU oder OAI-PMH. Normalereiweise im Web geben Programierschnittstellen JSON aus, dies ist das übliche Format für moderne Schnittstellen. JSON (“JavaScript Object Notation”) ist - so wie die Abkürzung es aussagt - ein Javaskript Datenformat, welches Ifnroamtionen in einer lesbaren Form speichert. JSON wird oft mit Ajax genutzt, um Informationen zwischen Client und Sever auszutauschen. Sowie auch XML lässt sich JSON im Browser anschauen und maschinell gut verarbeiten.
Erstes Beispiel für API: lobid-gnd
Auf lobid, kann man auf Datensätzen zugreifen, sie über die graphische Oberfläche konsultieren und diese auch in JSON Linked-Data herunterladen. Der Browser kann diese interpretieren, so dass wir die Informationen gut lesen können. Bei der Autovervollständigung kann man z.B. einem Namen suchen und erhält eine ID, welche uns den Zugriff auf dem JSON ermöglicht. Diese Option kann unter anderem die Vervollständigung eines Katalog dienen.
Zweites Beispiel für API: scrAPIr
Als weiteres Tool gibt es scrAPIr, ein Projekt vom MIT, welches für Menschen erstellt worden ist, die nicht unbedingt Programmieren können. Mit scrAPIr können Daten von Websiten angeschaut und bezogen werden, welche dursch die APIs der jeweiligen Webseiten übernommen werden. Auch kann man unter >_code hat man die Möglichkeit zu sehen, wie Abfragen in Javascript und Python gemacht werden können, und sich somit mit dem Abfragen mit Programmiersprachen auseinanderzusetzen.
Beispiel Google Books: https://scrapir.org/data-management?api=Google_Books
Metadatenstandard LIDO
LIDO steht für Lightweight Information Describing Objects und ist auf CIDOC Conceptual Reference Model - kurz CRM - basiert. Es handelt sich dabei um einem XML-Standard zur Beschreibung von Kulturobjekten und ist somit in Museen sehr vebreitet. Wir im Modul erst jetzt behandelt, da dieser Metadaten-Standard ein wenig anders geartet ist als andere Standards, die wir bischer angeschaut haben. CIDOC ist sehr abstrakt und somit auch nicht wirklich für die Anwedung gedacht. Es ist ein Modell, welcher eher den Aufbau von Konzepte dient. Dieser definiert URI für Konzepte und Relationen. LIDO macht sich CIDOC zur Nutzung, um daraus eine Sprache – eine Terminologie – zu erstellen und Museumsobjekte zu beschreiben. Als Vorteil entspricht LIDO dem Linked Open Data-Paradigma, da anhand der URIs Entitäten und Beziehungen eindeutig und nachschlagbar sind. Im Vergleich zu andere Metadaten-Standards, die Dokumente beschreiben, beschreibt LIDO Objekte ereignis-zentriert (Ereignisse als Entitäten). Damit jedes Museumsobjekt ist mit Ereignisse verbunden: so wird seine Geschichte beschrieben und sein Kontext definiert z.B. wie es erstellt worden ist oder wie wurde daran etwas geändert. Dazu sind Individuen, die an diese Ereignisse teilgenommen haben, werden auch erschlossen. Diese Struktur ist sehr intreressant, allerdings entsteht dabei ein grosses Problem: eine verlustfreie Transformation zu andere Formate ist schwer umzusetzen.
Struktur
Bei LIDO sind deskriptive Metadaten, administrative Metadaten und administrative Daten enthalten.
-
Deskriptive Metadaten: Identifikation und Klassifikation, die wir aus Dokumentzentrierte Metadaten auch schon kennen. Es sind beschreibende Metadaten und sagen aus um was es sich handelt, wie die Identifikation mit Titel, Name oder Masse. Die Klassifikation ist ein wenig anders, weil sich auch wieder an CIDOC orientiert, so müssen URIs und den genormten Vokabular entsprechen. Hinzu kommt das zentrlaes Element der Ereignisse sowie direkte Relationen zwischen Verschiedene Ressourcen.
- administrative Metadaten:
- Rechte (Objekt, Datensatz, Nutzung, Verbreitung, etc.)
- Datensatz (Identifikation, Urheber, etc.)
- Ressourcen (Digitalisat, Nachweis, etc.)
- Unterscheidung zwischen display elements und index elements: Idee, dass man damit einstellen kann wie etwas z.B. den Titel für den User und wie es im Suchindex erscheinen soll. Dies kann man für jede einzelne Angabe einstellen.
Zum Schluss eine Info von Herr Meyer: Wenn man sich weiter mit LIDO auseinandersetzten möchte, dann immer im Kopf behalten, dass LIDO wirklich ganz anders ist als alle andere Standards und dass was man darüber liest nur für LIDO gilt und nicht für den Rest. Persönlich finde ich das die Idee hinter LIDO spannend ist (aber vielleicht liegt es auch an meine Vorliebe für Museumsobjekte) und würde mich gerne da weiter einlesen. Dies werde ich allerdings nicht jetzt machen, sondern vermutlich lieber nach diesem vollen Semester.
Suchmaschinen und Discovery-Systeme 1/2
Installation und Konfiguration von VuFind
Auf https://vufind.org schauen wir zusammen die Stastistiken von Vufind. Es gibt es schon zehn Jahre, zwar ist der Entwicklungsteam wie bei OpenRefine diversifisiert, aber die Entwicklung wird vorwiegend von einzelne Personen vorangetrieben (eigentlich hauptsächlich von Demian Katz). Interessant ist, dass eine eine sehr aktive deutsche Anwendergemeinschaft gibt. Somit kann man versichert sein, dass man VuFind in den nächsten zehn Jahre benutzen wird (hier eine Präsentation von Herr Lohmeier darüber). Auf OpenHub finden man noch weitere Statistiken. Wenn man so anschaut wie regelmässig entwickelt wird, wer dazu beiträgt und wie viel, dann kann man indentifizieren, ob es sich lohn in einer Software zu inverstieren oder nicht. Es gibt zahlreiche Installationen bei Insitutionen. Wenn mann die unteren Beispiele anschaut, kann man erkennenm, dass einige Funktionen addiert ider angepasst worden sind. Mit der gleichen Software gibt es verschiedene Einstellungen, was natürlich zeigt, dass VuFind sich nach den Bedürfnisse anpassen lässt. Ein spannendes Beispiel ist noch BASE – Bielefeld Academic Search Engine, da hier von der ersten Version von VuFind sehr viel dazu selbst entwickelt worden ist. Es hat sich somit wirklich von VuFind entfernt, aber den Kern ist da und zeigt auch was damit möglich sein kann.
- Beispiel TU Hamburg: https://katalog.tub.tuhh.de
- Beispiel UB Leipzig: https://katalog.ub.uni-leipzig.de
Installation VuFind 7.0.1
Die Installation von VuFind erledigten wir gemeinsam anhand der offiziellen Anleitung für VuFind unter Ubuntu. Es gab einige Spezialitäten, auf welche man in unserem Fall achten musste. Diese Anmerkungen, welche auch zum Teil Anpassungen in der Installation benötigten, sind im Skript beschreiben. Aus diesem Grund gehe ich hier im Detail darauf.
Wichtig fand ich den Hinweis, dass in einem Best Practice Szenario nur eine Anwendung pro Sever installiert wird. Ziel davon ist Abhangigkeiten zu vermeiden (auch «dependency hell»). Heutzutage ist das nicht so eine Sache, da man es gut mit virtuellen Maschinen und Containers erledigen kann.
Testimport
Um VuFind tatsächlich nutzen und testen zu können, haben wir einige Daten in MARC21 mit folgenden Eingaben geladen:
/usr/local/vufind/import-marc.sh /usr/local/vufind/tests/data/journals.mrc
/usr/local/vufind/import-marc.sh /usr/local/vufind/tests/data/geo.mrc
/usr/local/vufind/import-marc.sh /usr/local/vufind/tests/data/authoritybibs.mrc
Die Installation hatte bei mir funktioniert und unter http://localhost/vufind waren die ca. 250 Datensätze zu finden. Aufgrund der Zeit wurde die Konfiguration von VuFinf als Aufgabe für die nächste Lektion gegeben.
Quellen: Blogeintrag zur Anreicherung, Fix, JSON, lobid, scrAPIr, CIDOC Conceptual Reference Model, VuFind, Präsentation von Herr Lohmeier über VuFind, BASE – Bielefeld Academic Search Engine, offiziellen Anleitung für VuFind unter Ubuntu und Skript